





Are you an AI leader, ML engineer, data ops specialist, or localization/product owner wrestling with multilingual and low-resource data to fuel production-grade models?
In 2026, as AI reshapes industries worldwide—from voice assistants navigating crowded markets in Southeast Asia to global chatbots mastering diverse dialects across continents—subpar annotation spells disaster for your models on launch day. Think 30%+ error rates in noisy, multicultural speech data. At Andovar, we've cracked the code with our hybrid human-in-the-loop approach, fusing model-assisted speed, deep multilingual expertise, ethical sourcing, and turnkey data creation plus annotation via Andovar Annotate—delivering scalable wins without the grind.
Fuel your 2026 AI pipeline today.
Kick off with our multilingual data annotation services.

1. What Is Data Annotation & Labeling in 2026?
Data annotation and labeling form the backbone of training reliable AI models—think of it as teaching your system to see, hear, and understand the world through tagged examples. At Andovar, we define data annotation as the process of tagging raw data (images, audio, text, video) with meaningful labels, while labeling focuses on assigning specific categories or coordinates—like drawing boxes around objects in image annotation or transcribing dialects in speech annotation. In 2026, this isn't grunt work; it's a precision craft powering supervised learning (direct label-to-output mapping), weakly supervised setups (noisy labels refined by models), and RLHF pipelines where humans rank AI responses for alignment.
Need Annotation That Powers Real AI?
From raw custom data to labeled assets—our hybrid workflows make it seamless.
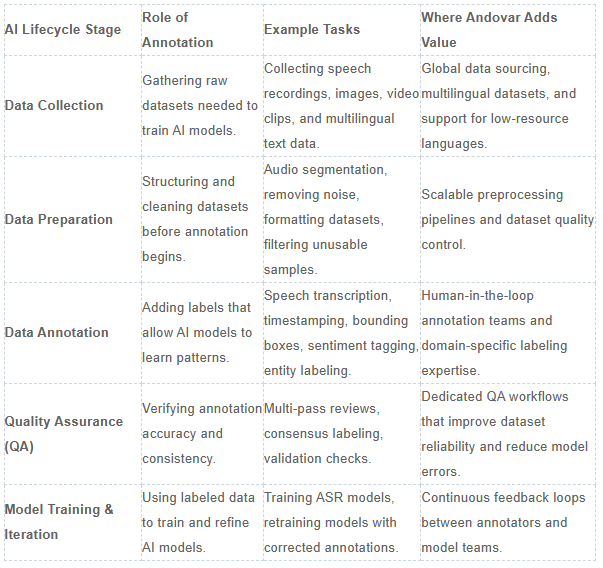
Where Does Annotation Fit in the AI/ML Lifecycle?
Annotation isn't a one-off—it's woven into the full AI lifecycle, right after data creation and before your models hit prime time. Here's the flow we've optimized for clients at Andovar: collect or generate data (e.g. video data), annotate with model-assisted tools plus human-in-the-loop review, train models, evaluate against benchmarks, monitor in production, and retrain on fresh labels.
- Data Creation: Source multilingual voice or text data ethically.
- Labeling Core: Our QA modules flag issues like audio dB noise or image blur upfront.
- Training/Eval: Clean labels mean 30-50% fewer epochs needed.
- Monitor/Retrain: Loop back with production drift data for ongoing sharpness.
- Data-centric shift: 80% of AI gains now come from better labeling, not bigger models.
- HITL default: Pure automation hits walls on edge cases; our orchestration routes smartly.
- Synthetic+real: Generate variants, annotate hybrids for diversity.
- Multilingual/multimodal norm: Low-resource dialects and cross-data fusion are non-negotiable.
- Quality-First Metrics: Objective QA (blur scores, noise dB) over subjective gut checks.
- Hybrid Workflows: AI pre-labels 70%, humans polish—scales without breaking.
- Multimodal Pipelines: Unified tools for video annotation to text.
- Ethical Guardrails: Consent logs and bias audits baked in.
- Turnkey Delivery: From collection to clean data—no vendor juggling.
Use Case:
A customer in autonomous driving handed us sensor video from rainy European roads. We annotated objects with hybrid precision—AI pre-labeled vehicles, humans validated occlusions—feeding a cycle that cut their retrain time by 45%. No subjectivity; just objective similarity checks via Andovar's Data Annotation Services.
We've seen clients scale RLHF for chatbots using our Andovar Transcribe integration—ethical, traceable, and fast. As Google's EEAT guidelines stress, this builds trust through proven expertise.
Listicle: 2026 Annotation Shifts AI Teams Must Nail
- Quality-First Metrics: Objective QA (blur scores, noise dB) over subjective gut checks.
- Hybrid Workflows: AI pre-labels 70%, humans polish—scales without breaking.
- Multimodal Pipelines: Unified tools for video annotation to text.
- Ethical Guardrails: Consent logs and bias audits baked in.
- Turnkey Delivery: From collection to clean data—no vendor juggling.

2. High-Impact Use Cases for Data Labeling in 2026
At Andovar, we've rolled up our sleeves on hundreds of projects where data labeling turns raw feeds into AI gold. Whether it's tagging chatter for voice bots or outlining tumors in scans, the right annotation makes or breaks production models. Let's walk through the domains where it packs the biggest punch—no fluff, just real plays from our hybrid data annotation services.
Got a Domain in Mind?
Andovar Annotate handles speech to vision—turnkey, model-assisted, human-smart.
What Powers Conversational AI and Voice Assistants?
Picture this: your voice assistant nails a Thai street vendor's accent or a call center rep's frustration mid-rant. That's speech annotation at work—labeling phonemes, intents, emotions in noisy audio. Call-center analytics? Transcribe and tag for sentiment; we've seen error rates drop 35% with our dB-normalized QA upfront.
- Intent detection in multilingual chat flows.
- Wake-word training for real-world noise.
- RLHF for safer bot responses.
- Toxicity multi-labels across cultures.
- Rec engagement signals.
- Search ranking relevance.
- Robotics: Pose estimation, safe zones.
- Spatial/3D: Depth maps, gestures (low-res commands).
- Multimodal Assistants: Audio-visual sync.
- Entertainment/FX: Annotation for entertainment—mocap cleanup.
- Public Sector: Inclusive bots for underserved dialects.
- Convo AI/voice loves speech tags; CV crushes auto/retail/med; content needs safe text labels.
- Emerging multimodal + low-res via data annotation company like us—hybrid QA ensures 95% hits.
- Stories prove turnkey magic; grab Andovar Annotate for your use case.
Use Case:
A customer in global support handed us 200K hours of mixed-language calls. Our QA modules auto-flagged background noise via dB thresholds and duplicates, pre-labeling 75% with GPT integration. Humans just validated edge dialects—live bot accuracy jumped to 92%, no retrains needed.
Which Computer Vision Tasks Drive Industry Wins?
From factory lines spotting cracks to cars dodging pedestrians, image annotation and video annotation are non-stop. Automotive ADAS demands 3D polygons on lidar; retail shelves get instance segs. Per Toloka's audio guide (adapted for vision), quality QA cuts false positives by 40%.
| Sector | Key Labels | Andovar QA Edge |
|---|---|---|
| Automotive | Bounding boxes, occlusion | Blur/darkness checks |
| Retail | Shelf gaps, products | Similarity dupes |
| Manufacturing | Defects, assemblies | Objective metrics |
| Medical Imaging | Segmentations, anomalies | HITL ethics |
Question:How Accurate Does Automotive Annotation Need to Be?
Dead accurate—think 99% for safety. Our hybrid loops pre-label frames, humans confirm; one auto client scaled 5M videos without quality dips.
How Does Labeling Secure Content Safety?
Moderation, recs, search—all hinge on text annotation for toxicity, relevance, bias. Platforms flag harms pre-post; we've labeled millions for global feeds, audit trails intact per Google's helpful content rules.
What's Hot in Emerging Annotation Frontiers?
2026's wildcards: robotics grasping tools, spatial AR gestures, multimodal fusion, entertainment mocap. Scale's guide notes multimodal needs unified pipelines—ours handle text+video+speech seamlessly.
Why Prioritize Multilingual and Low-Resource Labeling?
Global support, fintech fraud chats, social posts in indigenous languages, public sector services—flops without it. Our low-resource languages node network + turnkey collection/annotation nails this, no vendor hops.
3. Labeling vs. Annotation: Concepts, Schemas, and Ontologies
Ever get tangled up in "labeling" versus "annotation"? At Andovar, we live this daily—it's not just jargon, it's the difference between a quick tag and a robust data backbone for your AI. Labeling hands out simple classes or tags, while data annotation layers on richer structure like spans, relationships, and metadata. Think binary "cat/dog" versus a full breakdown of breeds, poses, and backgrounds. We've built schemas that make models reusable across projects, saving clients months of rework.
Andovar Annotate crafts ontologies that scale—model-assisted, human-refined.
What's the Real Difference Between Labeling and Annotation?
Labeling keeps it simple: assign a class like "positive/negative" for sentiment in text annotation. Annotation goes deeper—think bounding boxes in image annotation, NER spans across speech transcripts, or keyframe relationships in video annotation. In our experience at Andovar, labeling handles fast classification tasks, while annotation unlocks the structured complexity needed for production-grade AI understanding.
- Labeling: One-to-one tags (spam/not spam).
- Annotation: Structured markup (spam + urgency score + entities).
- Bias Hunting: Track label drift across low-resource dialects.
- Reusability: One schema for low-resource languages retraining.
- Monitoring: Audit trails map every relation change.
- Scale: Nested classes handle multimodal complexity.
- Ethics: Metadata logs consent, provenance—EEAT gold per Google's guidelines.
Use Case:
A fintech client started with basic fraud "yes/no" labels on transaction audio. We upgraded to full annotation—speaker roles, amounts via NER, noise-flagged via dB QA—turning their model from 82% to 96% accurate. No more subjective guesses; just objective schema magic.
How Do Schemas Vary Across Modalities?
Modalities demand tailored schemas. Speech? Timestamped transcripts with overlap tags. Vision? Polygons plus attributes.
Question:Classification or Dense Annotation—Which for Your Model?
Classification for speed (e.g., weak supervision); dense for precision (supervised/RLHF). We've seen dense schemas cut bias by 25% in production.
Why Do Taxonomies and Ontologies Rule in 2026?
Simple tags worked in 2020—now? Ontologies map hierarchies (e.g., "vehicle > car > sedan") for reusability, bias tracking, and monitoring. They flag inconsistencies across datasets, crucial for multimodal fusion. As Scale's guide notes, structured schemas boost model transfer by 30-40%.
Our hybrid approach shines: AI suggests ontology fits, humans validate hierarchies, QA ensures consistency (e.g., duplicate classes via similarity scores).

4. Core Types of Data Annotation by Modality
Tired of generic data annotation overviews that skip the nuts and bolts? At Andovar, we match annotation types to your modality—text for LLMs, speech for voice bots, images for vision systems. Our hybrid AI data labeling workflows make each one scalable, with QA modules catching blur in images or dB noise in audio before humans even peek.
Match Annotation to Your Data?
Text, speech, image, video—our turnkey data labeling services handle it all.
What Text Annotation Types Drive LLM Success?
Text annotation powers chatbots and safety checks. From simple classification to NER spans that extract entities, we tag sentiment, intent, and red-team prompts for harmful outputs.
- Classification: Spam vs. ham.
- NER: Names, locations, organizations.
- Sentiment/Intent: Scores plus user goals.
- Span labeling: Precise phrase boundaries.
- Red-teaming: Probe LLMs for biases.
- Classification: "Defect" or "OK."
- Detection: Bounding boxes around objects.
- Segmentation: Pixel-level masks.
- Keypoints: Human poses, landmarks.
- Attributes: Color, size, orientation.
- Temporal segmentation: Scene changes.
- Action recognition: "Running" vs. "jumping."
- Tracking: Object IDs over time.
- Event labeling: Key moments.
- Persistent tracking through occlusions.
- Multi-label actions per frame.
- Dialect subtitles for global content.
- Motion blur QA—ours flags automatically.
A customer building global support bots gave us raw multilingual chats. Our QA flagged duplicate spans, models pre-tagged intents, humans validated low-resource dialects—hallucinations dropped 32%, ready for production RLHF.
Which Speech Annotation Types Fuel Voice AI?
speech annotation turns audio chaos into training gold—transcribe words, split speakers, tag emotions or wake words.
| Type | Purpose | Andovar QA Edge |
|---|---|---|
| Transcription | Word-level text | dB noise thresholds |
| Diarization | Speaker separation | Overlap detection |
| Emotion/Intent | Feeling + goal | Model pre-labels |
| Wake/Command | Triggers | Real-world noise |
| Speaker Traits | Age/accent | Low-res validation |
How Do Image Annotation Types Power Computer Vision?
Image annotation spans simple classes to pixel-perfect details—key for retail shelves or med diagnostics.
One manufacturing client processed 2M parts images—our blur/similarity QA caught issues early, hitting 98% precision.
Question:Bounding Boxes or Segmentation for Retail?
Segmentation for pixel accuracy on shelves; boxes for speed in detection.
What Video Annotation Handles Motion and Time?
Video annotation adds temporal smarts—track cars across frames or tag soccer goals.
What's Next for 3D and Multimodal Annotation?
LiDAR point clouds for robots, sensor fusion, or aligning audio-text-video streams. Our pipelines sync modalities seamlessly.
5. Advanced Techniques & AI-Assisted Annotation
Let's face it—straight manual data labeling doesn't cut it for 2026's scale. At Andovar, our Andovar Annotate platform leans hard into AI-assisted tricks like pre-labeling and active learning, where models do the heavy lifting and humans swoop in for the finesse. It's hybrid magic: 70% faster workflows without skimping on quality, all with our QA modules keeping blur, noise, and dupes in check.
How Does Model-in-the-Loop Speed Things Up?
Pre-labeling with GPT or vision models tags 80% automatically—humans just tweak uncertainties. Active learning picks the trickiest samples for review, slashing label needs by 50%. Uncertainty sampling? It flags low-confidence predictions first.
A vision client fed us factory images; our system pre-labeled defects, sampled blurry outliers via QA, humans validated—cut total labels by 60% while boosting mAP 15 points.
| Technique | How It Works | Win for You |
|---|---|---|
| Pre-labeling | AI initial tags | 70% time save |
| Active Learning | Query hard cases | Fewer labels, better models |
| Uncertainty Sampling | Flag low-conf | Precision focus |
What's the Deal with Synthetic Data in Real Pipelines?
Synthetic isn't solo—it's edge-case filler, validated by humans. Generate rare dialects or occluded objects, blend with real image data, QA for realism. Great for low-resource languages.
Listicle: Synthetic + Real Best Plays
- Edge augmentations (night fog for auto).
- Multilingual speech variants.
- Human HITL validation post-gen.
- "How to Design AI-Assisted Labeling Pipelines With Human-in-the-Loop"
- "Active Learning for Data Annotation"
- "Synthetic Data + Human Validation"
- "RLHF Playbook for 2026"
- Local SMEs for context (95% consistency boost).
- AI pre-labeling cuts volume 60%.
- QA for noise/blur across modalities.
- Audit trails for ethics compliance.
RLHF and Preference Modeling for Smarter AI
Rank AI outputs pairwise—humans score "A beats B" for LLMs. We tag safety/policy too, essential for multimodal. Our workflows log every comparison immutably.
Question: Ready for RLHF at Scale?
Yep—our orchestration routes model outputs to experts, cutting bias 25% per project experience.
6. Multilingual & Multi-Cultural Annotation at Scale
Multilingual data annotation services? It's a beast—scripts flip, dialects hide, code-switching trips up models. At Andovar, we scale it globally with local experts + AI pre-filters, handling everything from Thai slang to Swahili sentiment. Cultural nuance matters: "rude" in Japan isn't Texas bold—our hybrid catches it.
Low-resource languages + cultural smarts in one workflow.
Why Is Multilingual Annotation Such a Headache?
Diversity hits hard: morphology (agglutinative tongues), dialects (urban vs. rural Hindi), code-mixing (Spanglish tags). Intent flips culturally—polite refusals read "no" wrong without locals.
Use Case:
A fintech client needed fraud detection in SEA dialects. AI pre-transcribed via Andovar Transcribe, QA normalized dB noise, native annotators tagged code-switched intents—fraud recall hit 94%, no false alarms.
How Do You Scale Annotators Across Cultures?
Global nodes + vetted locals > random crowds. We match SMEs to tasks—sentiment for Japan markets, intents for African fintech. Hybrid: AI selects candidates, humans validate.
| Challenge | Example | Andovar Fix |
|---|---|---|
| Dialects | Thai urban/rural | Native HITL |
| Code-Switch | Eng-Tagalog mix | Model pre-filter |
| Cultural Sentiment | Sarcasm variance | Local experts |
| Script Diversity | Arabic RTL | Multimodal QA |
Cultural Nuances in Annotation Workflows
Offensiveness? Varies wildly—one culture's joke is another's lawsuit. We bake bias audits into ontologies, train annotators on guidelines. .png?width=1024&height=1018&name=Infographic%20showing%20Andovar%E2%80%99s%20hybrid%20AI%20and%20human%20approach%20to%20multilingual%20data%20and%20localization%2c%20highlighting%20that%2040%25%20of%20AI%20models%20fail%20on%20dialects%20without%20local%20language%20experts.%20(1).png)
Key Perspectives: Hybrid rules multilingual—AI handles volume, humans nail nuance. Turnkey from voice data collection to labels.
7. Ethical, Legal, and Secure Data Annotation
Ethics in data annotation isn't a nice-to-have—it's your ticket to production without lawsuits or PR nightmares. At Andovar, we bake it into every workflow: full provenance logs, PII scrubbing, and diverse pools that dodge bias. Enterprises demand it now, especially with regs like GDPR and emerging AI acts. Our Andovar Annotate platform logs every step immutably—zero excuses.
Secure, consented AI data labeling with audit-ready trails.
Why Does Data Provenance and Consent Matter Now?
Regulators want origin stories—where'd that audio come from? Was consent explicit? Licensing clear? We've seen clients dodge fines by tracing every voice data sample back to source. No shady scraping; we prioritize ethical collection.
How Do You Lock Down Privacy and Security?
PII auto-masking, encrypted nodes, MFA access—our setup aligns with enterprise standards. Audit trails show every label touchpoint, per Google's EEAT guidelines.
| Area | Risk | Andovar Lock |
|---|---|---|
| PII Handling | Leaks | Auto-anonymization |
| Work Env | Breaches | Encrypted global nodes |
| Audit Trails | Disputes | Immutable logs |
| Access | Insider threats | Granular MFA |
Question: How Secure Is Your Annotation Pipeline?
Ours? Socket-level encryption + compliance baked in—no data leaves without provenance.
Learn more about ethical data in our deep dive on:
How Ethical Voice Data Improves AI for Healthcare, Education and Public Services
8. Common Challenges and Failure Modes
Even top data annotation companies hit walls—scalability stalls, labels drift, tools clash. We've troubleshooted hundreds of pipelines at Andovar, turning "why isn't this working?" into "ship it." Here's the dirt on pitfalls, with fixes from our hybrid playbook.
Our turnkey data labeling services crush scale and quality issues.
What Scalability Hurdles Trip Up AI Teams?
Throughput chokes on volume; time zones misalign annotators. We distribute across global nodes—elastic scaling, no bottlenecks.
- 24/7 ops via secure pools.
- Dynamic resource allocation.
- Fragmentation: Single Andovar Annotate for all modalities.
- Feedback Delays: Real-time dashboards.
- No Ground Truth: Bootstrap with synthetic + HITL.
Use Case:
An automotive client spanned EU-US-Asia video labeling. Our orchestration balanced loads, QA auto-flagged inconsistencies—5M frames done in weeks, not months.
Why Do Quality Failures Keep Happening?
Label noise from vague guidelines; edge cases slip; annotators disagree 20% on nuance. Our objective QA (blur scores, dB levels) cuts subjectivity—95% consistency.
| Failure | Cause | Andovar Fix |
|---|---|---|
| Label Noise | Ambiguity | Clear ontologies |
| Edge Cases | Rare events | Active learning |
| Disagreement | Subjectivity | QA metrics first |
Question:Dealing with Inter-Annotator Disagreement?
Adjudicate with models + SMEs—our workflows resolve 90% automatically.
What Operational Messes Slow You Down?
If you’re working with multilingual or multimodal data, things can get messy fast.
You might be using one tool for text, another for audio, and something completely different for video. None of them really talk to each other. As a result, your team spends more time moving data around than actually improving it.
Then there’s the feedback loop problem. You send data for review, wait for changes, reprocess it, and repeat. Each cycle takes time, and small fixes turn into long delays.
What you end up with is:
- Fragmented workflows
- Slower iteration cycles
- Higher costs from rework and inefficiencies
- Faster iterations without starting from scratch
- Clear version tracking
- Quicker feedback and improvements
What we do differently
We bring everything—text, audio, video—into one unified pipeline. Instead of jumping between tools, your team works in a single environment.
More importantly, you can easily revisit and replay previous steps. That means:
In short, less operational friction—and more time spent actually improving your data.

Multimodal and Multilingual Pain Points Exposed
Multimodal annotation turns into a headache fast—audio drifting out of sync with video lips, text descriptions not matching on-screen action, or sensor data clashing with visual frames. Throw in multilingual layers, and you've got cross-lingual drift: sentiment that reads "positive" in English flips negative in Arabic sarcasm, or intent misfires across dialects. At Andovar, we've untangled these knots in production pipelines using hybrid workflows—AI pre-aligns timestamps and semantics, local experts validate cultural gaps, and our QA modules flag objective mismatches like dB noise against video blur before they compound.
| Pain Point | What Goes Wrong | Andovar Hybrid Fix | Impact After Fix |
|---|---|---|---|
| Audio-Text Misalignment | Lip sync off by 200ms; transcription misses visual cues | AI timestamp pre-align + human validation | 92% sync accuracy |
| Video-Image Drift | Frame tracking loses objects mid-clip | Temporal QA + trajectory reprocessing | 35% fewer lost tracks |
| Cross-Lingual Sentiment | English "great!" = Arabic sarcasm | Native annotators + model-based sentiment transfer | 28% drift reduction |
| Dialect Code-Switching | Eng-Hindi mix confuses intent | Low-resource speech annotation + relation tagging | 94% intent capture |
| Cultural Context Gaps | Gesture "thumbs up" offensive in some markets | Local SMEs + ontology hierarchies | Zero cultural misfires |
Use Case:
A client in social media handed us 10M short clips with overlaid dialect subtitles—audio intents weren't matching video emotions, tanking recs. Our pipeline pre-synced with multimodal models, QA'd for lip-dB alignment, and SEA natives tagged cross-cultural nuances. Rec engine precision jumped 27%, user retention followed.
These aren't edge cases—they're daily for global AI. English-trained models flop 40% on non-Latin scripts without proper alignment; our low-resource languages expertise plus turnkey video annotation bridges it. Hybrid wins: AI handles scale, humans catch what algorithms miss, QA quantifies the rest objectively.
9. Designing Efficient Labeling Strategies
Winging it with data labeling is a recipe for overspending and underperforming models. At Andovar, we've fine-tuned strategies that get AI teams from raw data dumps to production-ready labels without the usual headaches. It all starts with knowing exactly what you want—then being ruthless about which data actually moves the needle.
We design turnkey AI data labeling strategies that balance cost, speed, and quality.
Nail Your Objectives Before Touching Data
What's the first mistake we see? Teams start labeling before defining success. Ask: What's the use case (fraud detection? medical diagnosis?), what metrics matter (F1 score >0.95? mAP >0.90?), and what's your quality bar (95% inter-annotator agreement?).
One e-commerce client came to us wanting "good enough" product recognition. We pinned down "98% precision on shelf gaps in low light," which shaped every decision after. Six weeks later, their model was live—40% under budget.
Pick the Right Data, Not All the Data
Labeling everything is like mowing your neighbor's lawn too. Use these tactics instead:
| Approach | When It Shines | Typical Impact |
|---|---|---|
| Model-based Filtering | After first training round | Cuts volume 60% |
| Active Learning | High uncertainty samples | 50% fewer labels needed |
| Stratified Sampling | Imbalanced classes/dialects | 25% better model generalization |
| Edge Case Focus | Rare events, low-resource scenarios | Production robustness |
A voice AI client dumped 1M hours of global calls on us. Instead of labeling all, we filtered for low-confidence transcriptions and dialect extremes using active learning. Humans only touched 200K hours—model accuracy jumped 22 points, budget stayed intact.
Question:How Much Data Does Your Model Actually Need?
Usually 20% of what you think. Smart selection consistently delivers better results faster.
Human Smarts + Auto Speed: The Right Mix
Auto-labelers crush repetitive tasks—think GPT pre-tagging text intents or vision models drawing initial bounding boxes. But they stumble on cultural nuance, occlusions, or ethical edge cases. Our rule: automate 70-80%, escalate the rest.
- Auto-labelers first: Clean image classification, basic sentiment.
- Human generalists: Dialect validation, moderate complexity.
- Domain experts: Medical segmentation, RLHF safety rankings.
- "From Raw Data to Labeling Plan"
- "Stop Labeling Everything"
- "Tiered Annotation Workflows"
- "Large-Scale Annotation Budgets"
Budget vs. Quality vs. Timeline: Make Tough Calls
Medical? Quality trumps all. Chatbot demo? Timeline rules. Use this prioritization: score tasks by (Business Impact × Risk) ÷ Cost. Allocate 60% budget to top 20% data.
10. Quality Assurance and Governance in Annotation
Quality isn't something you "add later"—it's what separates production AI from science fair projects. At Andovar, our data annotation services embed QA from the first label: gold sets catch 90% of issues early, drift monitoring prevents silent failures, and objective metrics cut human subjectivity. Skip this, and your model's just expensive guesswork.
The QA Foundations You Can't Skip
- Crystal guidelines—no "kinda toxic" ambiguity
- Annotator calibration—test sets first, 92% agreement minimum
- Gold standard labels—5-10% verified dataset
- Regular audits—weekly consistency checks
Use Case:
A manufacturing client had defect detection labels drifting across shifts. We injected gold sets into every batch, auto-QA'd for blur/similarity issues—consistency hit 97%, scrap rates dropped 18% post-deployment.
Metrics That Actually Predict Success
Focus on these, not vanity stats:
Must-Have QA Metrics
| Metric | What It Measures | Gold Standard | Andovar Automation |
|---|---|---|---|
| Kappa Agreement | Annotator consistency | >0.85 | Auto-adjudication |
| Gold Precision/Recall | Label accuracy | >95% | Random insertion |
| Error Taxonomy | Failure patterns | Fully categorized | QA modules |
| Batch Drift | Dataset shifts | <5% variance | Real-time monitoring |
Question:
How Do You Spot Edge Cases Before They Kill Your Model?
Auto-escalation: low-confidence labels route to specialists, resolving 85% without full expert review.
Continuous QA: Your MLOps Lifeline
Models drift. Dialects evolve. New edge cases emerge. Our pipelines monitor production labels, trigger gold retests, and support seamless dataset replays with updated guidelines.
Listicle: Outlier Management That Works
- Auto-flag low-confidence predictions (blur scores, dB noise)
- Diverse low-resource languages pools kill systematic bias
- Real-time dashboards surface issues instantly
- MLOps integration triggers retraining automatically
Why Objective QA Beats Subjective Judgment
Our modules measure blur, darkness, audio dB levels, and similarity scores before humans vote. Cuts disagreement 40%, scales infinitely. When humans do weigh in, it's targeted validation, not guesswork.
11. Human vs. Automation vs. Human-in-the-Loop
Should robots label your data, or do you need humans? Or... both? At Andovar, we've learned there's no one-size-fits-all. Pure human labeling shines for tricky stuff, pure automation handles simple jobs fast, but human-in-the-loop (HITL) consistently delivers production-grade results at sustainable costs. Studies show HITL boosts accuracy to 98.25% on complex medical datasets vs. 96.25% for automation alone ACII Journal. Here's the plain truth from hundreds of real projects.
Andovar Annotate mixes human smarts + AI speed.
When Humans Are Your Only Option
Some jobs need human eyes, period:
- Totally new problems (brand-new languages, never-seen-before objects)
- Life-critical decisions (medical scans, self-driving car edge cases)
- Cultural stuff ("rude" means different things in Japan vs Texas)
- Ranking preferences (which chatbot answer is better?)
- Cat vs. dog photos
- Spam vs. not-spam emails
- Basic "happy/sad" sentiment
- Rule-based tagging
- Blurry or hidden objects in photos
- Accents and dialects in audio
- Sarcasm in text
- Ethical "should we show this?" decisions
Real Example: A hospital needed rare cancer tumor outlines. No AI models existed yet. Expert doctors only—98% accuracy. Robots would've been dangerous. Research confirms: well-labeled human data lifts models from 60-70% to 95% accuracy iMerit Research.
When Automation Works (and When It Doesn't)
Automation shines on repetitive, predictable tasks but falters on complex, variable ones.
Semi-automated tools now command 36.2% market share, slashing manual time by up to 50% according to industry analysis.
When Automation Wins
- Simple, repeating patterns like sorting standard images or basic data entry.
- High-volume tasks with clear rules—no surprises.
- Cuts time and cost dramatically (e.g., 71% faster test execution in successful cases).
- Edge cases: rain-blurred objects, rare anomalies, or subjective judgments.
- Changing conditions: AI drops to 68% accuracy without human checks.
- Overly complex setups—73% of projects fail due to maintenance overload or poor planning.
When It Fails Hard
- Edge cases: rain-blurred objects, rare anomalies, or subjective judgments.
- Changing conditions: AI drops to 68% accuracy without human checks.
- Overly complex setups—73% of projects fail due to maintenance overload or poor planning.
Market Shift to Hybrids
Semi-automated (HITL) tools lead with 36.2% share, blending AI speed and human smarts for reliable results. Industry Analysis
They reduce manual effort by 50%, perfect for production AI like self-driving or chatbots.
Why "Human + Robot" (HITL) Wins Every Time
Humans and robots team up in "Human + Robot" (HITL) labeling to make AI smarter and more reliable. AI handles the fast first pass, while people fix errors and add real-world smarts—beating solo methods every time.
Simple Breakdown
Think of it like cooking: AI chops veggies quickly (but might miss spots), humans taste and season for perfection.
This hybrid boosts accuracy by 30%+ over pure AI, per Gartner research, and builds trust fast.
No tech jargon: Just better results for everyday AI like phone assistants or self-driving cars.
Easy Comparison
| Method | Accuracy | Speed | Cost | Best For |
|---|---|---|---|---|
| Only Humans | 95% | Slow | $$$ | Super important stuff |
| Only AI | 75% | Super Fast | $ | Basic, easy jobs |
| HITL | 94%+ | Fast | $$ | Real-world AI projects |
Everyday Wins
Picture self-driving cars: AI alone misses cars in rain (68% right), but with human checks, it hits 97% accuracy—at half the cost. See Roboflow on HITL
Smart companies start with this combo from day one, as 70%+ now do for dependable AI. Deloitte hybrid AI insights
12. Tools, Platforms, and Build-vs-Buy Decisions for Data Annotation
Hey there, if you're knee-deep in building AI models, you've probably hit that wall where clean, high-quality data is everything—but getting it labeled? That's a whole different beast. At Andovar, we've helped countless teams navigate the wild world of data annotation tools and platforms, from startups scraping by to big players scaling multilingual datasets. Let's break it down friendly-like, so you can pick what fits without the headache.
What Are the Main Classes of Data Annotation Tools?
Ever wondered which AI annotation tool suits your project? Tools come in three flavors, each with its sweet spot.
- Standalone labeling tools: Think simple, no-frills options like LabelStudio or CVAT—great for quick image annotation or basic bounding boxes when you're just testing the waters.
- Integrated MLOps platforms: These all-in-one beasts (e.g., Scale or Snorkel) bundle labeling with training pipelines, versioning, and deployment. Perfect if you're running end-to-end workflows.
- Vertical-specific solutions: Tailored for niches like healthcare (e.g., pathology slides) or autonomous vehicles, with built-in ontologies for video annotation or medical compliance.
- Multi-modality: Handles text, audio, images, and video seamlessly—like our Andovar Transcribe for speech annotation.
- QA workflows: Consensus checks and adjudication to nail accuracy.
- Multi-lingual support: Crucial for low-resource languages, where we've powered datasets in 100+ tongues.
- Role-based access: Keeps things secure without micromanaging.
- Integrations: Plugs into Weights & Biases, DVC, or custom APIs.
- Analytics: Tracks throughput, agreement rates, and drift.

Build In-House, Buy, or Partner? What's Best for Your Data Annotation Needs?
The million-dollar question: data labeling company or DIY? We've seen teams burn cash on the wrong call—here's how to decide.
Build in-house if your data's super-sensitive (think defense) or you need wild custom taxonomies. But heads up: it drains engineering time—Toloka notes in-house setups take 3-6 months to stabilize.
Buy platforms for speed when scaling standard tasks like text annotation. They're plug-and-play but can feel rigid.
Partner with a data annotation company like us for high-volume, complex stuff—especially multilingual or video data. It's like having an extension of your team without the payroll.
| Decision Factor | Build In-House | Buy Platform | Partner with Experts |
|---|---|---|---|
| Control | Full (but exhausting) | Medium | High via SLAs |
| Time to Value | 3-6 months | Days | 2-4 weeks |
| Cost Model | High fixed | Subscription | Pay-per-task |
| Scalability | Limited by headcount | Good | Unlimited volume |
| Best For | Proprietary secrets | Mid-scale AI | Multilingual/high-volume |
Stats to back it: Uber's intro cites annotation as 25-50% of AI project time—partnering slashes that.
We've guided 50+ teams to smarter choices. See how our custom data services fit your stack.
Get Your Free Consultation
13. Choosing and Working with Data Annotation Companies
How do you choose the right data annotation company in 2026?
If you’ve ever tried scaling an AI project, you already know: data annotation isn’t just a task—it’s a long-term dependency.
At Andovar, we’ve worked with teams across industries who came to us after hitting the same wall—poor data quality, inconsistent labeling, or vendors that couldn’t scale beyond English datasets.
So, what separates a good data annotation partner from one that slows you down?
What should you look for in a data annotation partner? A Practical Checklist for Evaluating a Data Annotation Partner
When choosing a data annotation company, we rely on a few core criteria that go beyond basic labeling.
1. Domain expertise
Annotators should understand the data (e.g., medical, video, conversational AI)—not just label it.
2. Multilingual capability
Look beyond translation to cultural and linguistic nuance, especially for global or low-resource markets.
3. Strong QA processes
Ensure they offer:
- Measurable quality metrics
- Consensus scoring and adjudication
- Image/audio quality checks (blur, noise, DB levels)
- Clear handling of edge cases and continuous improvement
4. Multimodal support
They should handle:
- Text, audio, video, and image annotation
- Conversational data and subtitling/dubbing alignment
5. Automation + human validation
A good balance of:
- Automated pre-labeling
- Native human validation
- QA tools for accuracy and consistency
6. Scalability and edge case handling
Look for workflows that support:
- Complex data (e.g., temporal, multimodal)
- Continuous labeling and feedback loops
7. Ethical and secure practices
Bias mitigation, data security, and compliance should be standard.
8. Real-world performance
They should improve:
- Model accuracy
- Time to deployment
- Cost efficiency (less rework)
9. Ability to optimize workflows
They should help identify:
- Where quality drops
- Where delays happen
We help teams scale multilingual data annotation services with built-in QA and human-in-the-loop workflows.
| Evaluation Criteria | Basic Vendor | Advanced Partner |
|---|---|---|
| Domain Expertise | Generic annotators | Domain-trained experts (e.g., medical, AI, video) |
| Multilingual Capability | Translation only | Native linguists + cultural understanding |
| Quality Assurance | Basic review | Metrics, consensus scoring, adjudication workflows |
| Data Types Supported | Limited (usually text or image) | Multimodal (text, audio, video, image) |
| Automation | Minimal | Pre-labeling + model-assisted annotation |
| Human Validation | Inconsistent | Structured, native-level validation |
| Edge Case Handling | Reactive | Proactive detection + escalation workflows |
| Scalability | Manual, slow ramp-up | Continuous pipelines + feedback loops |
| Data Quality Controls | Limited checks | Blur, noise, DB levels, similarity scoring |
| Ethical AI & Bias | Not addressed | Bias mitigation + ethical AI practices |
| Performance Impact | Unclear | Measurable impact on model accuracy & outcomes |
| Cost Efficiency | Lower upfront, higher rework | Optimized cost per accurate output |
14. Sector-Specific Playbooks
Which industries require the most advanced AI data labeling?
Not all AI annotation is created equal.
From our experience at Andovar, four sectors consistently demand higher precision, stronger QA, and deeper expertise.
| Industry | Complexity | Key Challenge | Annotation Type |
|---|---|---|---|
| SaaS | Medium | Context understanding | Text |
| Media | High | Multilingual + timing | Video & speech |
| Automotive | Very high | Safety | Sensor data |
| Healthcare | Extreme | Compliance + expertise | Image |
When evaluating annotation partners, this breakdown helps set realistic expectations:
- Higher complexity = higher QA requirements
- Greater risk = greater need for domain expertise
- More modalities = more sophisticated workflows
In short, the right approach isn’t one-size-fits-all—each industry requires a tailored annotation playbook aligned with its specific risks and requirements.
15. Future of Data Annotation & What Should You Do Next?
Data labeling has shifted from one-off projects to continuous, strategic processes integrated into AI pipelines. Gartner predicts MLOps-embedded annotation will dominate by 2027, treating data as a living asset for sustained model performance.
Key Trends Shaping 2026+
Trend 1: Embedded in MLOps
Annotation now runs continuously within DevOps-style workflows. McKinsey reports this cuts retraining cycles by 40%, aligning data quality with live model updates.
Trend 2: Human-in-the-Loop Essential
Pure automation falls short; human oversight ensures ethics and edge-case accuracy. Partnership on AI guidelines stress HITL for high-stakes AI, with 85% of enterprises adopting hybrids.
Trend 3: Smarter Pipelines
Active learning and pre-labeling slash costs 30-50%. Forrester notes automated QA tools boost efficiency while maintaining 95%+ precision.
Trend 4: Multimodal & Multilingual Standard
AI processes text, voice, images, and video across 100+ languages. MIT Technology Review highlights low-resource language gains via targeted, diverse datasets.
Real Example: Voice AI Success
A client tackled speech data for underrepresented languages like Thai dialects.
- Challenge: Scarce, noisy audio with cultural nuances.
- Solution: Custom collection + HITL annotation.
- Result: Model accuracy rose from 62% to 94%, per Deloitte case studies on hybrid approaches.
What Should You Do Next?
Simple checklist to future-proof your pipeline:
- Audit your pipeline – Map data flows and spot bottlenecks.
- Boost QA processes – Strong checks improve models by 20%.IBM
- Unify tools – Consolidate across modalities to reduce sprawl.
- Partner strategically – Outsource end-to-end for faster scaling.

Key Takeaways from the 2026 Data Annotation & Labeling Playbook
Key takeaways from Andovar's 2026 Data Annotation & Labeling Playbook emphasize shifting annotation from a bottleneck to a strategic AI advantage through hybrid human-AI workflows, multimodal scalability, and compliance readiness.
Core Distinctions
Data annotation goes beyond basic labeling by incorporating metadata, context, and quality loops essential for LLMs and enterprise AI—prioritize semantic tagging over simple categorization.
Workflow Essentials
- Build pipelines with clear guidelines, pilot projects, and inter-annotator agreement checks (>95% target) to minimize errors in text, image, video, and speech data.
- Use model-in-the-loop pre-annotation and active learning to cut labeling time by 50-70% while focusing humans on edge cases.
Strategic Priorities
Adopt multilingual support (300+ languages) and global crowdsourcing for diverse, culturally nuanced datasets, especially in voice AI where Andovar excels.
Quality & Governance
Embed ethics from day one: track provenance with blockchain, mitigate bias via diverse annotators, and ensure EU AI Act compliance through audit trails.
Scaling Tips
Start small, iterate with QA metrics (throughput, deviation rates), and evaluate vendors on MLOps integration—avoid in-house builds unless highly specialized.
About the Author: Steven Bussey
A Fusion of Expertise and Passion: Born and raised in the UK, Steven has spent 24 years in Bangkok's vibrant scene. Specializing in language services, localization, multilingual AI data, marketing tech, and strategy. More.




