





Introduction
Why voice data is the future of AI
If you’re building anything with a microphone and a model behind it, speech and voice data are now as important as your model architecture. From virtual assistants to in‑car voice control to contact‑center analytics, we’re all leaning on audio more than ever—and your AI is only as good as the data you feed it.
The broader AI community increasingly recognizes that data quality—not just model size—drives performance. Stanford’s AI Index Report has repeatedly highlighted the growing importance of data-centric AI approaches.
At Andovar, we’ve seen this shift up close. Teams come to us because their speech recognition works fine in the lab—but falls over when real customers with real accents and real background noise start talking. The pattern is always the same: training on narrow, convenient datasets leads to high error rates, bias, and frustrated users, while high‑quality, diverse speech data gives models the chance to generalize to the messy, human world.
Accent-related performance gaps in ASR systems have been documented in independent research, including studies showing significantly higher word error rates for under-represented dialects.
In this guide, we’re pulling back the curtain on how we think about speech data, voice data, and the mix off‑the‑shelf datasets and custom speech data that actually works in production. We’ll talk through dataset types, key applications, real‑world challenges, metadata, ethics, annotation, and practical strategies for building better audio datasets—always from our perspective as a provider of multilingual voice data collection services and custom speech data solutions.
Chapter 1
What are the main types of speech and audio data?
Why should you care about different audio data types?
Not all audio is created equal. If you’re training an AI model, the type of audio you choose—conversational speech, read prompts, environmental sounds, music, synthetic voices—will quietly dictate what your system can and can’t do. In our projects at Andovar, one of the first questions we ask is: “What exactly do you want your model to hear and understand?” Because that answer drives the entire data strategy.
At a high level, you’re usually working with three big buckets: speech data, non‑speech audio (environmental sounds, events), and music or other structured audio. On top of that, you need to decide how much of your training set should be natural versus synthetic audio, and where custom voice data is worth the investment.
In our projects at Andovar, one of the first questions we ask is: “What exactly do you want your model to hear and understand?” Because that answer drives the entire data strategy.
Speech data: the heartbeat of voice AI
Speech data is the core ingredient for ASR, voice assistants, dictation, and most conversational AI. Industry guides are very clear: your models’ accuracy, robustness, and fairness depend heavily on the diversity and quality of the speech data you train them on.
Large open initiatives such as Mozilla’s Common Voice project were created specifically to improve diversity and accent coverage in speech datasets.
From our side, we spend a lot of time helping clients choose the right mix of:
Conversational speech
Real dialogues between two or more people—phone calls, customer service interactions, casual chats. This is gold for training natural language understanding and dialog systems because it captures turn‑taking, interruptions, hesitations, and the way people actually talk, not how they read scripts.
Research on conversational corpora such as the Switchboard dataset has long demonstrated the importance of real dialog data for robust ASR performance.
Read speech
Speakers reading pre‑written prompts or scripts. This is ideal when you need clean, well‑controlled data for tasks like text‑to‑speech, pronunciation modeling, or baseline ASR training. Many large public and commercial speech datasets lean heavily on read speech because it’s easier to collect at scale.
Datasets such as LibriSpeech, built from read audiobooks, have become standard benchmarks in speech recognition research.
Spontaneous speech
Unscripted, natural speech—people thinking aloud, explaining something in their own words, or chatting freely. This is where models learn to handle disfluencies, filler words, corrections, and diverse phrasing. Several leading dataset guides emphasise that spontaneous speech is crucial if you care about performance in real‑world conditions, not just lab tests.
In practice, we almost always recommend a mix: maybe read speech to cover a wide vocabulary and accents efficiently, plus conversational and spontaneous speech in the domains and languages that matter most to you.
Environmental sounds and non‑speech audio
If you’re working on sound event detection, smart home devices, automotive safety, or context‑aware systems, non‑speech audio matters just as much as speech:
Sound classification
Recognising and categorising sounds like alarms, footsteps, rain, or machinery. Guides to audio datasets stress that capturing a wide range of environments and recording conditions is essential if you want models that work outside of pristine labs.
Benchmark datasets such as AudioSet demonstrate how diverse environmental audio improves generalisation across real-world scenarios.
Audio event detection
Detecting specific events in a stream—doorbells, glass breaking, car horns, or specific machine failures. Here, you need carefully designed datasets with accurate timestamps and labels so models can learn to pick events out of long, noisy recordings.
Community challenges such as the DCASE (Detection and Classification of Acoustic Scenes and Events) initiative highlight the importance of high-quality, time-aligned annotations.
In many of our projects, we combine speech data with non‑speech events to help clients build systems that know not just what was said, but what else was happening around the microphone.
Music and other structured audio
Music datasets are their own world: recommendation engines, genre classification, mood detection, or generative music models. The same principles apply—clear objectives, good metadata, and enough diversity—but the features are different: tempo, key, instrumentation, and so on.
For most of our clients, music is less central than speech, but the lesson is the same: you can’t just throw “audio” at a model; you need the right kind of audio for your objective.
Synthetic vs natural audio: when should you fake it?
Another big design choice is how much synthetic audio you use. Synthetic speech and sounds can be powerful tools, but they can’t fully replace real, messy human recordings.
Recent research into data augmentation and synthetic speech shows that while synthetic data improves robustness, it performs best when combined with real recordings.
Synthetic audio
Machine‑generated speech or sound. It’s cheap to scale and great for controlled experiments, edge‑case testing, and augmenting under‑represented scenarios. We often see teams use synthetic audio to stress‑test models or pad specific phonetic combinations and acoustic conditions.
Natural audio
Real recordings from real environments and speakers. This is what gives your model real‑world robustness and captures accents, emotions, disfluencies, and background noise. It’s harder and more expensive to collect, especially if you want ethical speech data with clear consent and licensing, but it’s also where most of the value lies.
Our stance at Andovar is simple
Custom, natural data is always better for performance, but we know it’s not always practical to go 100% custom. That’s why we push a mixed model—baseline crowdsourced or off‑the‑shelf datasets for speed and cost, then targeted custom speech data to fill the gaps that matter for your product.

Where Andovar’s studios and network fit in
To make all of this usable at scale, you need infrastructure.
We lean on:
- Eight professional recording studios for controlled, high‑quality speech data.
- A large global contributor network to capture natural speech in the wild—especially for low‑resource languages and regional accents.
- Flexible workflows that let us blend natural recordings, synthetic augmentation, and multilingual coverage.
If you want to dive deeper into how we design and run these projects, our multilingual voice data collection services and custom speech data pages go into more detail.

More information on Andovar Studios can be found at their website:
Key takeaways
Different types of audio—conversational speech, read prompts, spontaneous speech, environmental sounds, music—serve different AI use cases, and choosing the wrong mix can quietly cap your model’s performance.
Natural, custom voice data gives you realism and control, while synthetic and off‑the‑shelf speech corpora provide speed and scale; in our experience, the best results come from combining them rather than picking one camp.
Investing up front in the right speech and audio types, across the accents and languages your users actually speak, pays off much more than endlessly tuning models on the wrong data.
Struggling to choose the right speech data mix?
We’ve helped teams in finance, customer service, and consumer electronics design speech datasets that match real users—not just lab conditions. If you want a quick sense check on your current data plan, we’re happy to review it.

Chapter 2
How is speech and audio data used in real‑world AI?
What does voice data actually power today?
If you look around your day, voice is everywhere: smart speakers, in‑car assistants, call‑center bots, dictation tools, even subtle things like automatic subtitles. All of these systems live or die on the quality of their speech data and voice data.
The global shift toward voice interfaces isn’t theoretical. It’s already happening at scale.
According to Statista, the number of digital voice assistants in use worldwide is projected to reach 8.4 billion devices, exceeding the global population.
From our standpoint at Andovar, the most common use cases we support fall into a few big categories:
- Speech recognition (ASR)
- Natural language processing (NLP)
- Voice biometrics
- Industry-specific applications in healthcare, automotive, customer service, and finance
The models may differ, but the common denominator is always the same: high-quality, representative speech data.
Speech recognition: turning talk into text
Automatic speech recognition (ASR) is what turns spoken words into text. It’s the backbone of virtual assistants, transcription tools, voice search, and more. Modern guides to speech and audio datasets consistently point out that ASR quality is directly tied to how diverse and well‑annotated your training data is—particularly across accents, noise conditions, and speaking styles.
We typically see teams use:
- Broad, multilingual corpora to get a base model working.
- Targeted custom speech data projects to close gaps:
- domain vocabulary (medical, legal, financial)
- specific accents
- Noisy environments (call centers, vehicles, public spaces)
Natural language processing: making speech meaningful
Once speech becomes text, natural language processing(NLP) extracts meaning:
- Intent detection
- Sentiment analysis
- Entity extraction
- Dialogue management
- Next-best action prediction
Many industry guides emphasise that speech data must align with downstream NLP objectives. Otherwise, you end up with accurate transcripts that still miss the user’s intent.
In real projects, this means:
- Curating speech examples that match real user intents
- Annotating not just transcripts but also:
- Intents
- Slots
- Sentiment labels
- Capturing how people actually speak — including disfluencies, corrections, and informal phrasing
This is why we so often combine data collection, transcription, and multilingual data annotation services in a single workflow.
Voice biometrics: recognising who is speaking
Voice biometrics systems use voiceprints to verify or identify speakers.
It’s used in:
- Banking authentication
- Call-center identity verification
- Secure system access
Because voice carries information about a person’s physiology and sometimes their health or emotional state, many ethical and legal frameworks treat it as sensitive biometric data.
For your datasets, this means:
- Clear, informed consent
- Explicit licensing terms
- Transparent usage boundaries
- Balanced demographic representation
You also need careful demographic coverage across age, gender, and accent groups to prevent unfair rejection rates. We help clients source this kind of ethical speech data with explicit licensing and robust metadata, so they know exactly what they can and can’t do with it.
Ethical speech data isn’t optional in biometrics — it’s foundational.
How are different industries using speech and audio datasets?
The patterns are similar across sectors, but the details vary.
Healthcare
Voice is increasingly explored for:
- Clinical documentation
- Medical dictation
- Patient triage
- Early condition detection via vocal biomarkers
Healthcare applications require:
- Strict privacy safeguards
- Explicit consent
- Domain-specific vocabulary
- High-accuracy transcription in controlled environments
Even small error rates can have serious consequences.

Automotive
In-car voice systems must work in:
- Road noise
- Wind noise
- Multiple passengers speaking
- Different speeds and acoustic conditions
This requires robust datasets collected inside vehicles, across accents, and in real driving conditions — not just studio recordings.

Customer Service & Contact Centers
This is one of the most mature speech AI sectors. Companies use speech data for:
- Call transcription
- Quality assurance
- Agent assistance
- Sentiment analysis
- Compliance monitoring
Many organizations begin with generic English-heavy datasets, then quickly discover they need:
- Accent coverage
- Multilingual expansion
- Domain-specific vocabulary
- Real call-center acoustic conditions
That’s typically when custom speech data becomes essential.

Financial Services
Banks and fintech firms use speech AI for:
- Voice authentication
- Fraud detection
- Automated customer support
- Regulatory call monitoring
Here, the combination of biometric sensitivity, compliance requirements, and domain vocabulary makes high-quality, ethically sourced data non-negotiable.

The bigger picture: Why data strategy matters
Across all sectors, there is a consistent pattern:
- Off-the-shelf datasets get you started quickly.
- Custom voice data gets you production-ready.
Models rarely fail because of architecture alone. They fail because the dataset didn’t reflect real users, real environments, or real language patterns.
If you’re building in any of these areas, starting with high‑quality off‑the‑shelf datasets can be a quick win—but you’ll likely need custom voice data to really standout.
Key takeaways
- Speech and audio datasets underpin nearly every modern voice experience — from ASR and NLP to biometrics and industry-specific tools — and their quality is directly tied to real-world performance.
- Each industry has unique data requirements: healthcare demands strict privacy, automotive requires noisy real-world recordings, and contact centers need domain and accent coverage.
- Voice biometrics and other sensitive applications require explicit consent, clear licensing, and balanced demographic representation to ensure legal compliance and fair performance.
- A hybrid strategy — combining off-the-shelf datasets with targeted custom data — consistently delivers stronger outcomes than relying on either alone.
Need speech data across multiple languages and regions?
We can source native speakers, design prompts, and collect labelled audio in both major and low‑resource languages—backed by clear consent and licensing.

Chapter 3
What are the biggest challenges in working with audio datasets?
Why is building good speech datasets still so hard?
On paper, building a speech dataset sounds straightforward: record speakers, label the audio, train a model.
In practice, every team that touches speech data runs into the same recurring problems:
- Bias
- Scalability constraints
- Poor or inconsistent audio quality
- Missing languages and accents
- Low-resource markets
- The trade-off between real and simulated audio
From our experience at Andovar, the technical obstacles are only half the story. The other half is operational: recruiting the right contributors, coordinating collection across multiple countries, managing privacy and consent, and keeping quality high while you scale.
Speech data is not just a machine learning asset. It’s a logistical, ethical, and demographic challenge rolled into one.
In practice, every team that touches speech data runs into the same headaches: bias, scalability, noise, missing languages and accents, low‑resource markets, and the constant trade‑off between real and simulated audio.
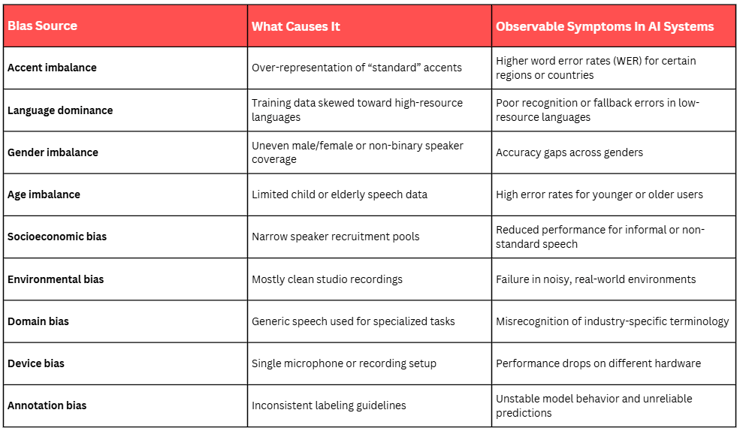
Data bias: who does your model really understand?
Bias in audio datasets usually comes from simple imbalances:
- Too much data from one accent group
- Limited age diversity
- Underrepresentation of certain genders
- Overly clean, studio-only recordings
- Lack of real-world noise conditions
Research on demographic bias in ASR has documented cases where models perform significantly better on some accents than others when training data is skewed.
Typical sources of bias include:
- Over-representation of US English or “standard” accents
- Limited coverage of older or younger speakers
- Scripted read speech with minimal spontaneous variation
- Studio recordings that fail to reflect noisy, real-world environments
The impact is real. Some users get seamless experiences. Others are constantly misheard — which damages trust and can have serious consequences in healthcare, finance, or legal contexts.
At Andovar, we design datasets with explicit demographic and environmental targets, not just whoever is easiest to recruit. Balanced data does not happen accidentally.
Scalability: how do you grow without losing quality?
Scaling from a 100-hour pilot to a 5,000-hour multilingual dataset is where many projects break.
The operational overhead increases dramatically:
- Contributor recruitment
- Session scheduling
- Consent management
- Metadata standardization
- Quality control
- Secure file handling
Without structure, large audio datasets quickly become inconsistent and difficult to manage.
In our projects, scalability relies on:
- Eight professional recording studios for controlled, repeatable sessions
- A global contributor network for in-the-wild data
- Standardized consent flows and recording instructions
- Structured metadata schemas from day one
Even then, we often recommend a hybrid approach:
- Use off-the-shelf datasets for baseline coverage
- Invest custom budget only where it materially improves performance
Scaling is not just about collecting more hours. It’s about scaling without degrading signal quality.
Data augmentation: helpful boost or crutch?
Data augmentation techniques — adding noise, altering pitch, simulating microphones, mixing background sounds — can significantly improve robustness without collecting entirely new speech.
They are widely used to:
- Simulate different environments
- Expand acoustic diversity
- Stress-test edge cases
- Improve model generalization
However, augmentation has limits.
Our rule of thumb:
- Use augmentation to expand diversity and stress‑test models.
- Don’t use it as an excuse to skip collecting real custom voice data in critical languages, accents, and use cases.
Augmented data can’t fully replace natural variability, but it’s a great force multiplier if your base dataset is well designed.
Audio quality: “garbage in, garbage out” still applies
Poor audio quality can quietly sabotage an otherwise strong model.
Common issues include:
- Clipping
- Echo
- Excessive background noise
- Inconsistent sampling rates
- Poor microphone placement
Best-practice dataset guides emphasize consistent formatting, appropriate dynamic range, and clearly defined recording standards as foundational to ASR robustness.
This is why we invest in:
- Dedicated studio spaces
- Controlled recording environments
- Clear contributor instructions
- Defined audio thresholds and QC processes
For in-the-wild data — which is essential for realism — we implement structured validation pipelines to filter out unusable recordings before they reach model training.
High-quality data is not a luxury. It is a prerequisite.
Language and accent diversity: the long tail problem
Most public speech datasets heavily focus on:
- Major global languages
- Standardized accents
- High-resource regions
But real user bases rarely look like that.
If your customers speak:
- Regional dialects
- Low-resource languages
- Mixed or code-switched speech
You will hit performance gaps quickly.
UNESCO estimates that nearly 40% of the global population does not have access to education in a language they speak or understand well — highlighting how linguistic diversity is far broader than dominant digital languages.
If your user base lives in the long tail—regional dialects, low‑resource languages, code‑switching—you’ll quickly hit gaps.
UNESCO estimates that nearly 40% of the global population does not have access to education in a language they speak or understand well — highlighting how linguistic diversity is far broader than dominant digital languages.
Industry resources on multilingual datasets stresses:
- Including diverse dialects from the outset
- Attaching robust metadata (language, region, accent tags)
- Measuring performance per demographic group
This is one of the reasons we built our contributor network the way we did: to be able to recruit speakers in low‑resource languages and less‑documented dialects, not just the usual suspects.
The “long tail” is not niche. It’s where competitive advantage lives.
Low‑resource languages and emerging markets: where generic data fails
Collecting speech data in low‑resource languages is harder because:
- Fewer standardized corpora exist
- Recruitment networks are limited
- Dialects vary significantly
- Technical infrastructure may be inconsistent
Yet many of the fastest-growing voice AI markets are in exactly these regions.
This is where custom speech data really shines:
- Local partner recruitment
- Prompts reflecting local culture and usage
- Clear, locally appropriate consent and compensation flows
- Explicit licensing for regulatory confidence
More organizations are recognizing that scraping or purchasing “mystery-source” corpora for emerging markets creates brand and regulatory risks they cannot afford.
Real data vs simulated data: finding the right mix
There is always tension between real recordings and simulated data.
Real data provides:
- Authentic accents
- Natural disfluencies
- Emotional nuance
- True environmental variability
Simulated data provides:
- Controlled edge cases
- Rare-event coverage
- Efficient stress testing
Best-practice guidance across the speech AI community recommends:
- Using real data as the foundation
- Using simulation and augmentation strategically
Our approach mirrors that:
Start with real custom voice data in your core scenarios, then use simulation and augmentation to explore edge cases.
Not the other way around.
Case study:
Improving ASR for finance with a hybrid data approach
Here’s how this looks in practice.
A financial services client approached us with a common issue:
Their ASR performed well on standard accents in clean conditions but struggled with:
- Regional accents
- Older speakers
- Noisy customer calls
This mirrors patterns seen in ASR evaluation research when training data over-represents certain demographics.
Working together, we:
- Analysed their existing off‑the‑shelf speech datasets and live traffic to identify under‑served accents and environments.
- Designed a custom speech data collection program targeting those gaps, recording both studio‑quality and realistic call‑center audio through our studios and remote contributors.
- Used a mix of real and augmented data to expose the model to typical line noise, over‑talk, and background chatter.
- Added detailed annotations—speaker turns, domain terminology, call outcomes—using our multilingual data annotation services to support both ASR and downstream analytics.
The result was a significant reduction in error rates on the previously under‑served groups and far fewer calls requiring manual review, in line with improvements reported when ASR models are fine‑tuned on better‑balanced speech datasets.

What this shows
- Before: error rates increase sharply for under-represented accents
- After: rebalanced training data narrows performance gaps across accent groups
Key takeaways
- The hardest problems in speech AI — bias, scalability, quality, and coverage — are data problems first, model problems second.
- Augmentation and off-the-shelf corpora are useful accelerators, but they cannot replace well-designed, ethically sourced custom voice data.
- Demographic targets, consent frameworks, metadata design, and QA processes should be treated as core product decisions — not afterthoughts.
- Teams that treat data as a first-class asset are better positioned for performance, fairness, and the coming wave of AI regulation focused on provenance and accountability.
Worried your speech data might be biased?
We can audit your existing speech datasets for accent, demographic, and environment coverage, then design targeted collection and annotation projects to close the gaps.
Ask us for a dataset review
Chapter 4
Why does metadata matter so much for speech data?
What is metadata in speech datasets (and why should you care)?
When people talk about “more data,” they usually mean more hours of audio.
But in real production projects, what often saves the day isn’t more hours — it’s better metadata.
Metadata is simply data about your data:
- Who is speaking
- In what language
- With which accent
- In what environment
- Under what technical conditions
- Under which rights and consent terms
Industry research on data governance and AI lifecycle management consistently emphasizes that structured metadata transforms raw data into a reusable asset.
The OECD AI Principles stress the importance of traceability, documentation, and data governance throughout the AI lifecycle — all of which rely heavily on structured metadata.
Without metadata, you have a folder full of WAV files.
With metadata, you have a dataset you can query, audit, balance, and safely reuse.
At Andovar Data, we regularly see teams realize — often too late — that poorly structured metadata creates more friction than a lack of audio hours ever did.
How does metadata make speech data actually usable?
Consider a few very common questions:
- “Can we test performance just on female speakers over 60 from rural regions?”
- “Can we exclude speakers who withdrew consent?”
- “Can we retrain using only noisy in-car recordings?”
- “Can we evaluate model fairness across accent groups?”
If your dataset is properly tagged, these are simple filters.
If not, you are facing:
- Weeks of manual sorting
- Re-annotation projects
- Legal uncertainty
- Or decisions made without reliable data
Good metadata enables you to:
- Filter by speaker characteristics (age, gender, region, accent, language)
- Filter by environment (studio, car, street, home, office)
- Track recording conditions (sample rate, microphone type, device)
- Enforce licensing and privacy constraints
In multilingual speech projects, metadata is what makes scale manageable. Without it, your dataset becomes opaque.
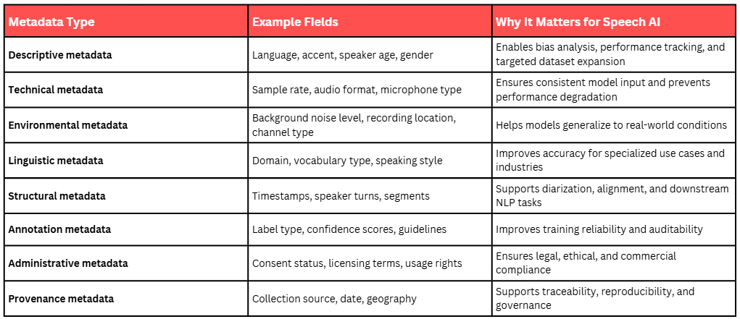
What types of metadata do you actually need?
Best-practice guidance in data management frameworks consistently separates metadata into four core categories.
The FAIR Data Principles (Findable, Accessible, Interoperable, Reusable), widely adopted in research and AI data governance, emphasize structured metadata as essential to making datasets reusable and auditable.
Descriptive metadata
Describes who is speaking and what is being said.
Examples:
- Speaker age
- Gender
- Region
- Native language
- Accent
- Topic or domain
- Emotion or speaking style
Why it matters:
- Enables demographic balancing
- Supports bias evaluation
- Allows targeted retraining
Technical metadata
Describes how the audio was captured.
Examples:
- File format (WAV, FLAC)
- Sample rate
- Bit depth
- Channel count
- Microphone type
- Recording device
- Recording distance
Why it matters:
- Ensures consistent preprocessing
- Supports acoustic modeling
- Prevents quality degradation during scaling
Administrative metadata
Describes ownership and legal constraints.
Examples:
- Licensing terms
- Usage rights
- Consent status
- Expiry dates
- Geographic restrictions
Why it matters:
- Protects against regulatory risk
- Enables traceability
- Supports AI governance compliance
As global AI regulation increases, traceable consent and documented data provenance are becoming non-negotiable.
The European Union’s AI Act highlights documentation, traceability, and data governance as core requirements for high-risk AI systems — reinforcing the need for structured metadata.
Structural metadata
Describes how the dataset is organized.
Examples:
- Segment boundaries
- Timestamps
- Speaker turns
- Alignment between audio and transcript
- Annotation layers
Why it matters:
- Enables training sequence models
- Supports diarization
- Allows downstream NLP alignment
At Andovar, we adapt metadata schemas to each custom speech data project — but we keep them aligned with recognized governance and interoperability standards so datasets remain future-proof.
How does metadata improve model performance?
Metadata is not just for compliance or file management. It directly impacts model quality.
Well-structured metadata allows you to:
- Build balanced training and evaluation splits
- Prevent speaker leakage between training and test sets
- Monitor performance across demographic groups
- Identify underperforming accents or environments
- Fine-tune models strategically
Research on bias in speech systems repeatedly shows that performance disparities become visible only when models are evaluated per demographic group — something that is impossible without detailed metadata.
In short, metadata allows intentional improvement.
Without it, model iteration becomes guesswork.
What are some best practices for metadata in speech projects?
Across both our own projects and external governance frameworks, several patterns consistently emerge:
Start with a schema
Define your metadata fields before collection begins.
Changing schemas mid-project creates inconsistencies that are difficult to repair.
Use controlled vocabularies
Standardize:
- Language codes
- Accent labels
- Environment categories
- Device types
Inconsistent labeling reduces dataset reliability.
Combine automation and human review
Automation works well for:
- File properties
- Sample rates
- Technical tags
Human review is necessary for:
- Accent classification
- Emotion labeling
- Complex linguistic tagging
Treat consent and rights as first-class metadata
Consent status and licensing terms should sit alongside speaker and technical tags — not in a separate spreadsheet.
This is essential for ethical speech data and regulatory readiness.
We embed these principles into our multilingual data annotation services so metadata quality is maintained in the same workflows that generate transcripts and labels.
Why metadata is becoming even more critical
As AI systems move into regulated environments — finance, healthcare, automotive — documentation requirements are increasing.
You are no longer just training models. You are demonstrating accountability.
Metadata enables:
- Auditability
- Provenance tracking
- Reproducibility
- Fairness evaluation
- Regulatory reporting
It transforms datasets from temporary assets into long-term infrastructure.
Key takeaways
- Metadata is the difference between “a lot of audio” and a structured, reusable speech dataset you can search, audit, and improve intentionally.
- Descriptive, technical, administrative, and structural metadata each serve different purposes — from model fairness to regulatory compliance.
- Well-designed metadata directly improves model performance by enabling balanced evaluation and targeted retraining.
- As AI governance frameworks expand, metadata is becoming a strategic requirement — not a technical afterthought.
Need a metadata schema that actually supports your AI roadmap?
We can help you design or retrofit metadata for existing speech datasets, and build new multilingual voice data collection projects with governance in mind from day one.
Talk to us about your speech metadata
Chapter 5
How do you collect speech data ethically and protect privacy?
Why is ethical speech data suddenly such a big deal?
Voice is personal.
A recording can reveal someone’s identity, emotional state, health indicators, accent, age range, and sometimes even their location. As voice interfaces expand into banking, healthcare, automotive systems, and everyday devices, regulators and users are asking tougher questions:
- Who owns this data?
- How was it collected?
- What exactly can you do with it?
- Can it be deleted if requested?
Regulatory pressure is increasing globally, and so is public scrutiny.
The European Union’s AI Act places strong emphasis on data governance, documentation, traceability, and risk management for high-risk AI systems — including systems trained on biometric or sensitive data.
Industry leaders increasingly define ethical speech data collection around four core pillars:
- Informed consent
- Transparency
- Fairness
- Accountability
We follow the same principles at Andovar Data because, in our view, this is where the market is heading — and compliance is quickly becoming a competitive advantage.
As voice interfaces move into banking, healthcare, and everyday devices, regulators and users are asking tougher questions: “Who owns this data? How was it collected? What can you do with it?”
What legal frameworks do you need to think about?
The specific rules depend on where you operate, but several major frameworks consistently shape speech data practices.
GDPR (European Union)
Under GDPR, voice recordings qualify as personal data if they can identify an individual. Biometric voiceprints may fall under “special category data,” requiring enhanced protection.
Core requirements include:
- Clear legal basis (typically explicit consent)
- Data minimisation
- Purpose limitation
- Right of access and erasure
- Accountability and documentation
European Commission overview of GDPR principles
CCPA and Similar U.S. State Laws
California’s CCPA (and related state laws like CPRA) emphasize:
- Transparency about data collection
- User rights to access and delete data
- Restrictions on selling or sharing personal information
These frameworks reinforce the need for clear documentation of how voice data is collected and used.
Sector-Specific Regulations
Certain industries impose additional requirements:
- Healthcare (HIPAA in the U.S.)
- Financial services regulations
- Children’s data protections (e.g., COPPA)
If speech data contains protected health information or financial identifiers, compliance obligations multiply.
The common thread across all frameworks is simple:
You must know what you are collecting, why you are collecting it, and under what consent and licensing terms — and you must be able to prove it.
What does informed consent look like in practice?
Consent is not a checkbox buried in fine print.
Ethical speech data practices require participants to genuinely understand how their voice will be used.
Best practice includes:
- Plain-language explanations of what is being collected (audio, transcripts, metadata)
- Clear description of commercial use and AI training
- Disclosure of third-party sharing
- Explanation of cross-border transfers
- Defined retention periods
- Easy withdrawal mechanisms
Consent should be:
- Explicit (opt-in, not opt-out)
- Documented
- Linked to individual recordings through metadata
At Andovar, we design multilingual consent flows aligned with local legal guidance and cultural expectations. Ethical speech data must be defensible — not just operational.
How do you respect privacy and autonomy in voice projects?
Legal compliance is the floor. Ethical responsibility goes further.
Privacy-respecting voice data collection emphasizes:
- Data minimisation
- Anonymisation where feasible
- Clear usage boundaries
- Strong security practices
The OECD AI Principles highlight transparency, human-centered values, and accountability in AI system design, including responsible data handling.
In practice, that means:
- Collecting only the speech data necessary for the project
- Removing or hashing direct identifiers where possible
- Separating identifying metadata from raw audio
- Restricting access to sensitive recordings
- Allowing participants to opt out of specific downstream uses
- Implementing encryption and secure storage protocols
This is especially critical in healthcare, education, and financial applications, where speech data may contain sensitive personal information.
How do you tackle bias and fairness ethically?
Ethics is not only about privacy. It is also about fairness.
Studies on ASR bias have repeatedly shown higher word error rates for underrepresented demographic groups when datasets are skewed.
For example, academic research has documented substantial error rate disparities across racial and accent groups when training data lacks diversity.
From an ethical standpoint, this creates two responsibilities:
1. Responsible Collection
Design datasets that:
- Avoid over-representation of dominant accents
- Include meaningful demographic coverage
- Capture real-world environmental diversity
- Include low-resource languages where relevant
If you never collect diverse data, you cannot build fair systems.
2. Responsible Evaluation
You must measure performance:
- Per accent group
- Per language
- Per age bracket
- Per gender
Not just global averages.
Fairness requires visibility — and visibility requires metadata.
This is where custom speech data projects for minority accents and low-resource languages play a critical ethical role. Without intentional sampling, bias persists invisibly.
Why a mixed model (custom + OTS) is often the most ethical choice
We strongly believe in custom speech data because it offers:
- Clear provenance
- Explicit consent
- Full traceability
- Defined licensing
However, building every dataset from scratch is rarely necessary.
Best practice in multilingual speech AI increasingly favors a hybrid approach:
- Use off-the-shelf datasets for baseline coverage
- Use custom speech data to close ethical and performance gaps
From an ethical perspective:
- Off-the-shelf datasets are acceptable only when provenance, licensing, and consent are clearly documented.
- Custom datasets provide greater defensibility for high-risk, sensitive, or regulated use cases.
As AI regulation tightens, more companies will be asked:
“Can you prove where your training data came from?”
For many generic corpora, the answer may be uncertain.
For structured, consent-based custom datasets, the answer is clear and documented.
Ethical readiness is rapidly becoming a market differentiator.
Our view is that as AI regulation tightens, more companies will be asked: “Can you prove where your training data came from?"
The ethical pipeline in practice
An ethical speech data pipeline typically follows a structured flow:
Recruitment → Consent → Collection → Anonymisation → Secure Storage → Licensing & Documentation
Each stage maps to legal and ethical principles:
- Recruitment → Fair representation
- Consent → Legal basis and transparency
- Collection → Data minimisation
- Anonymisation → Privacy protection
- Storage → Security and access control
- Licensing → Accountability and traceability
Ethics is not one policy document. It is a pipeline.
Key takeaways
- Ethical speech data collection is built on informed consent, transparency, fairness, and accountability — principles reinforced by global privacy and AI governance frameworks.
- Voice recordings are personal data in many jurisdictions and may qualify as biometric or sensitive data, requiring enhanced protections.
- Fairness requires intentional demographic sampling and performance evaluation across groups — not just overall metrics.
- A hybrid model combining vetted off-the-shelf datasets with custom, consent-driven speech data provides both efficiency and defensibility.
- As AI regulation tightens worldwide, documented provenance, consent, and metadata will move from “nice to have” to mandatory.
Need help designing consent flows for speech data?
We can provide language‑specific consent templates and processes that align with global privacy standards, then embed them into your custom speech data projects so you have a clear audit trail.
Talk to us about consent & compliance
Chapter 6
How do you annotate speech and audio data the right way?
Why does annotation make or break your speech model?
You can collect the best audio in the world, but if your labels are inaccurate or inconsistent, your model will still learn the wrong lessons.
For speech data, annotation is far more than transcription. It involves capturing:
- Who is speaking
- What is being said
- How it is being said
- What the speaker means
- What is happening acoustically around the speaker
In our experience at Andovar, many teams underestimate annotation complexity. Projects often begin with simple transcription, only to expand into requirements like:
- Speaker diarization
- Timestamp alignment
- Named entity tagging
- Intent labeling
- Sentiment or emotion tagging
- Acoustic or environmental classification
Annotation is the step where raw audio becomes training signal. When annotation quality is inconsistent, performance bottlenecks often appear — even when the underlying models are strong.
That’s where multilingual data annotation services and solid guidelines really start to pay off.
What makes speech and audio annotation so challenging?
Speech annotation introduces complexities that rarely exist in text-only datasets.
Layered information
Speech carries multiple signals simultaneously:
- Linguistic content
- Tone and prosody
- Emotional signals
- Background sounds
- Speaker identity
Each layer may require separate annotation passes or multi-label workflows.
High variability
Speech data includes:
- Regional accents
- Code-switching between languages
- Filler words and disfluencies
- Overlapping speakers
- Informal phrasing
These variations make consistent labeling significantly more difficult than structured text.
Subjectivity
Some annotation categories require human interpretation, including:
- Emotion classification
- Intent detection
- Pragmatic meaning
- Ambiguous entity references
Even well-trained annotators may disagree without clear guidelines.
Scale Explosion
Speech datasets scale rapidly. One hour of audio can generate:
- Thousands of tokens
- Multiple annotation layers
- Multiple metadata records
Best-practice guidance consistently emphasizes defining annotation goals, schema, and consistency standards before scaling. Otherwise, projects spend more time correcting labels than training models.
How can technology help without replacing humans?
The most effective annotation pipelines follow a human-in-the-loop model.
Automation improves speed and efficiency. Humans provide nuance, cultural context, and quality control.
Automation Strengths
Automation can:
- Generate draft transcripts using ASR
- Suggest timestamps and segmentation
- Provide preliminary diarization
- Pre-label common entities or acoustic tags
Human Strengths
Human annotators excel at:
- Correcting transcription errors
- Resolving ambiguous speech
- Labeling intent and emotion
- Handling low-resource languages
- Capturing cultural context
Research from Google and academic partners shows that human correction of machine-generated transcripts significantly improves training dataset quality compared to fully automated labeling pipelines.
The most effective workflows combine machine efficiency with human judgment — especially in multilingual and domain-specific datasets.
Why do annotation guidelines matter so much?
Inconsistent annotation guidelines are one of the fastest ways to undermine dataset quality.
Without shared standards, annotators may:
- Interpret intent differently
- Label emotions inconsistently
- Segment speech differently
- Apply inconsistent transcription rules
Industry data governance frameworks strongly emphasize standardized annotation schemas and controlled vocabularies.
The Linguistic Data Consortium (LDC) highlights that structured annotation standards and annotator training significantly improve dataset consistency and reproducibility in speech corpora.
Our standard annotation approach
At Andovar, annotation projects typically include:
Project-specific annotation guidelines
Clear instructions supported by examples and edge cases.
Annotator training and pilot testing
Small-scale pilot rounds help identify ambiguity before full production.
Inter-Annotator Agreement (IAA) monitoring
We measure agreement rates to detect systematic confusion and refine guidelines.
The goal is consistency. If two annotators hear the same clip, they should produce functionally equivalent labels.
How do you keep annotation ethical and sustainable?
Annotation introduces ethical considerations beyond data collection.
Privacy protection
Annotation workflows must:
- Protect sensitive speech content
- Restrict access to identifiable recordings
- Secure transcripts and metadata
- Follow consent limitations
Annotator wellbeing
Some speech datasets contain sensitive or distressing material. Ethical workflows include:
- Content flagging and filtering
- Workload management
- Support protocols for sensitive content exposure
Cultural and labeling bias
Emotion and sentiment labeling can vary across cultures. Annotation schemes must account for:
- Cultural interpretation differences
- Linguistic context
- Region-specific communication norms
Fair compensation and reasonable workloads also directly improve annotation consistency and long-term data quality.
Ethical annotation is both a compliance requirement and a quality driver.
Where do custom vs off‑the‑shelf datasets fit?
Off-the-shelf speech datasets can often be enhanced through improved annotation and metadata enrichment.
Many clients bring existing corpora that require:
- Additional labeling layers
- Consistency correction
- Ethical documentation improvements
- Updated metadata schemas
However, some annotation requirements cannot be retrofitted easily, including:
- Detailed consent metadata
- Domain-specific labels
- Custom intent taxonomies
- Demographic metadata tied to speaker recordings
This is why many speech AI best-practice frameworks recommend designing annotation schemas alongside data collection strategies.
Custom speech data allows annotation requirements to be embedded from the start, resulting in richer, more reliable training datasets.
Key takeaways
- Annotation converts raw audio into usable training data. Poor or inconsistent labeling is one of the most common hidden bottlenecks in speech AI performance.
- Speech annotation is uniquely complex because it involves layered signals, subjective interpretation, and large-scale data processing.
- Human-in-the-loop workflows deliver the best balance between efficiency and accuracy, especially for multilingual and low-resource datasets.
- Structured annotation guidelines, training, and quality monitoring are essential for dataset consistency and reproducibility.
- While off-the-shelf datasets can be upgraded through re-annotation, custom speech data enables deeper ethical compliance, richer metadata, and domain-specific labeling from the beginning.
Running into annotation quality issues?
If your transcripts and labels are inconsistent across languages or vendors, we can help redesign your guidelines and workflows, then relabel critical speech data through our multilingual data annotation services.
Fix your speech annotations
Chapter 7
How do you build better audio datasets in practice?
“Better” does not automatically mean “bigger.”
Across serious multilingual audio dataset guides and speech AI benchmarks, the highest-performing corpora are not simply the largest — they are the ones that are:
- Clearly aligned to defined objectives
- Diverse in the right dimensions
- Consistently annotated
- Well-documented in terms of provenance and consent
Research from Stanford and other institutions evaluating speech systems has repeatedly shown that performance gaps often stem from distribution mismatch, not model architecture limitations. When training data does not reflect real-world usage conditions, error rates increase significantly across underrepresented groups.
Koenecke et al. (Stanford University) found that several commercial ASR systems had substantially higher word error rates (WER) for Black speakers compared to white speakers, demonstrating how dataset imbalance translates directly into measurable performance gaps.
When we design datasets with clients, we start with alignment questions:
- Who are the end users, and how do they actually speak?
- Which languages and accents matter most commercially?
- Which acoustic environments must the model survive in?
- What regulatory or privacy risks exist in the deployment markets?
From there, we design a mix of off-the-shelf datasets and custom voice data that meets those objectives efficiently.
How do you expand dataset diversity without losing control?
Diversity is not optional if you care about fairness and robustness.
Multiple speech AI studies have shown that unbalanced corpora lead to predictable blind spots. The goal is structured diversity — not random expansion.
Key dimensions of dataset diversity
We typically recommend planning diversity across four primary dimensions:
1. Demographic Coverage
- Age groups
- Gender identities
- Regional representation
- Socio-economic variation
2. Language and accent variety
- Major commercial languages
- Regional dialects
- Minority and low-resource languages
- Code-switching patterns
The Mozilla Common Voice project, one of the largest open multilingual speech corpora, highlights how underrepresented accents significantly affect model generalization.
Mozilla Common Voice demonstrates that balanced accent representation improves robustness across speech recognition benchmarks.
Source:
3. Environmental diversity
- Studio recordings
- Home environments
- In-car recordings
- Public spaces
- Noisy vs quiet settings
Models trained only on clean studio audio frequently degrade when exposed to real-world background noise.
4. Scenario Diversity
- Scripted prompts
- Semi-scripted interactions
- Spontaneous conversation
- Task-oriented dialogue
This is where multilingual voice data collection services and contributor networks matter operationally. It is easy to define diversity targets; it is much harder to recruit, brief, monitor, and scale contributors across 20+ accents or regions while maintaining quality.

How do you handle privacy and ethics while scaling up?
Scaling data collection does not reduce ethical responsibility — it increases it.
Speech data privacy guidance across jurisdictions consistently emphasizes:
- Informed consent
- Transparency of use
- Data minimization
- Secure storage
- Clear withdrawal mechanisms
Under GDPR, voice recordings are considered personal data when they can identify an individual.
The European Data Protection Board (EDPB) clarifies that biometric and voice data can qualify as personal data under GDPR, requiring lawful basis and strict processing controls.
In larger-scale projects, we typically:
- Standardize consent flows across regions
- Store consent and licensing status as structured metadata
- Embed data minimization from the start
- Separate identifying information from training data where possible
When consent status and licensing terms are machine-readable, you can filter datasets later by rights category — which becomes critical as AI regulation intensifies globally.
This is what allows you to credibly describe your corpus as ethical speech data rather than simply “collected audio.”
Why does high‑quality training data matter so much?
Model architectures evolve rapidly. Foundation models and end-to-end ASR systems continue to improve.
But high-quality, well-targeted training data remains one of the strongest performance levers available.
Academic benchmarking consistently shows that carefully curated training data reduces:
- Generalization error
- Overfitting to dominant speaker groups
- Downstream bias
- Model instability across environments
Well-balanced custom speech data often reduces the need for heavy post-processing corrections or domain adaptation tricks.
We see this repeatedly in practice:
- Models trained on balanced datasets require fewer corrective layers.
- Once you measure performance per demographic or acoustic group, targeted custom data collection becomes easier to justify internally.
- Predictability improves when training distributions mirror deployment reality.
Better data leads to more explainable model behavior — and fewer unpleasant surprises after deployment.
How do the pieces fit together in a real pipeline?
A practical “better dataset” pipeline typically looks like this:
1. Define objectives
- Business goals
- User demographics
- Deployment environments
- Risk tolerance
2. Audit available off-the-shelf datasets
- Coverage gaps
- Licensing clarity
- Consent documentation
- Accent or demographic imbalance
3. Design custom speech data collection
- Targeted language and accent recruitment
- Environment-specific recording
- Clear consent and metadata tagging
4. Apply structured annotation
- Transcription standards
- Diarization
- Intent or entity tagging
- Consistent metadata schema
5. Validate with representative test sets
- Measure performance per group
- Benchmark across environments
- Identify systematic bias
6. Deploy and monitor
- Track drift over time
- Rebalance datasets as user demographics evolve
- Maintain documentation for compliance reviews
This objective → strategy → collection → annotation → validation → deployment funnel is echoed across serious multilingual dataset guides — but it must always be customized to your product and risk profile.
Key takeaways
- Building “better” audio datasets is about alignment, diversity, and consistency — not simply accumulating more hours of audio.
- Structured diversity planning across demographic, linguistic, environmental, and scenario dimensions directly improves robustness and fairness.
- A mixed strategy using off-the-shelf datasets for baseline coverage and targeted custom speech data for high-risk or high-value gaps is often the most efficient approach.
- Embedding privacy, consent tracking, and metadata governance into the dataset from day one creates both stronger models and stronger regulatory defensibility.
- As scrutiny around AI data provenance increases, documentation and traceability will become competitive advantages — not just compliance requirements.
Want your dataset to be high‑quality, not just high‑volume?
We can design an end‑to‑end process—collection, preprocessing, annotation, and QC—that keeps your audio datasets clean, diverse, and ready for production training.
Talk to us about dataset quality
Chapter 8
What is the future of training data for speech recognition?
Is the future really “data‑centric” for speech AI?
Model architectures are evolving rapidly. Transformer variants, end-to-end ASR systems, and large audio-language models continue to push benchmarks forward.
But in serious production environments, the dominant trend is clear: teams are becoming data-centric.
That means:
- Improving dataset coverage
- Expanding demographic and linguistic diversity
- Strengthening metadata and documentation
- Reducing bias through structured sampling
- Tightening consent and licensing traceability
Rather than endlessly tuning hyperparameters, teams are improving the training signal itself.
Andrew Ng, one of the most prominent advocates of data-centric AI, argues that systematically improving data quality often delivers larger gains than model architecture changes once you reach a certain baseline.
In our own work at Andovar, the biggest jumps in performance rarely come from swapping architectures. They come from:
- Fixing demographic imbalance
- Adding real-world acoustic diversity
- Improving annotation consistency
- Filling low-resource language gaps
Better inputs still beat cleverer tweaks.
How will multilingual and low‑resource data evolve?
For years, speech AI was heavily English-centric. That is changing.
Open multilingual corpora and commercial multilingual audio datasets are expanding rapidly, often with explicit goals around inclusion and global accessibility.
One of the most significant signals is the growth of large, permissively licensed speech corpora.
Meta’s XLS-R model was trained on 436,000 hours of publicly available speech data across 128 languages, demonstrating that scale plus multilingual diversity can dramatically improve cross-lingual performance.
This shift reflects two realities:
- Voice is often the most natural interface in markets with limited literacy or limited keyboard access.
- Companies expanding globally cannot rely on English-heavy corpora and expect consistent performance.
Looking ahead, we expect:
- Larger crowdsourced multilingual speech datasets with improved licensing transparency
- Greater investment in low-resource languages
- Accent-sensitive training and evaluation frameworks
- Regional data partnerships instead of centralized scraping
And strategically, hybrid approaches will dominate:
- Public corpora for broad baseline coverage
- Targeted custom speech data for competitive or regulatory edge
That mixed model aligns with what we consistently recommend: use wide baselines, then invest in precision where it matters most.
Will synthetic and self‑supervised data replace human recording?
Models like wav2vec 2.0 demonstrated that pretraining on large amounts of unlabeled audio can significantly reduce the amount of labeled data required.
Baevski et al. (Facebook AI Research) showed that wav2vec 2.0 achieved state-of-the-art results while using up to 100× less labeled data compared to previous approaches.
This has major implications for low-resource languages and domains where annotation is expensive.
We expect to see more workflows that:
- Pretrain on massive unlabeled corpora
- Fine-tune on smaller, high-quality custom speech datasets
- Use synthetic speech for targeted phonetic balancing
- Generate augmentation data for robustness testing
However, synthetic data raises new questions:
- Does it preserve real demographic diversity?
- Does it encode bias from source models?
- Is provenance clearly documented?
- Can it replace naturally occurring spontaneous speech?
In our view, synthetic and self-supervised methods are powerful accelerators — but not replacements for thoughtfully collected, ethically sourced speech data with documented consent and traceable origins.
They reduce labeling costs. They do not eliminate the need for real-world diversity.
How will regulation and data provenance change the game?
One of the biggest structural shifts coming to speech AI is around data provenance.
Research into dataset auditing has highlighted how many widely used datasets lack clear documentation around:
- Demographics
- Licensing
- Consent models
- Collection methodology
The broader AI community has already responded with structured documentation frameworks.
“Datasheets for Datasets” (Gebru et al., 2018) proposed standardized documentation describing motivation, composition, collection process, recommended uses, and limitations of datasets.
That framework is increasingly referenced in responsible AI guidelines and procurement requirements.
Looking forward, we expect:
- Regulators asking explicitly: “Where did this training data come from?”
- Enterprise customers requiring documented provenance
- Expanded use of dataset datasheets for speech corpora
- Metadata schemas that include consent status and usage rights
- Greater scrutiny of scraped or weakly documented datasets
Large language and speech models trained on loosely documented data may face increasing commercial friction in regulated industries like healthcare, finance, and automotive.
Provenance is becoming a competitive advantage.
Companies that can show:
- Clear recruitment methods
- Explicit consent documentation
- Structured metadata
- Defined licensing boundaries
…will be better positioned as AI oversight tightens globally.
That’s exactly why we design our custom speech data and multilingual voice data collection services around traceable workflows, clear licensing, and robust metadata. We believe companies that can show that level of provenance will be far better placed as rules tighten.
What does the long-term trajectory look like?
The future of speech recognition training data will likely combine:
- Massive multilingual pretraining
- Smaller, precision-engineered custom datasets
- Synthetic augmentation for robustness testing
- Standardized dataset documentation
- Stronger governance frameworks
In other words:
Scale will matter.
But structure will matter more.
The winning datasets will not just be large — they will be:
- Diverse
- Traceable
- Well-annotated
- Ethically sourced
- Properly documented
And as regulation evolves, that documentation layer may become just as important as the audio itself.
Key takeaways
- The future of speech recognition is decisively data-centric; improving dataset diversity, balance, and documentation often delivers larger gains than architecture tweaks.
- Multilingual and low-resource speech data will expand rapidly, supported by large-scale pretraining and hybrid public/custom strategies.
- Self-supervised and synthetic methods reduce labeling burdens but do not replace the need for authentic, diverse, ethically collected human speech data.
- Provenance and dataset documentation (e.g., datasheets) are moving from optional to essential as regulatory and enterprise scrutiny increases.
- Teams that invest early in traceable, well-documented, ethically sourced speech datasets will be better positioned for both performance and compliance in the next phase of AI regulation.
Need future‑proof, auditable speech data?
We design custom speech data and multilingual voice data collection projects with provenance, licensing, and documentation built in, so you’re better prepared for audits and future regulation.
Talk to us about data provenance
Chapter 9
Why off‑the‑shelf speech data isn’t enough on its own
Is off‑the‑shelf speech data good enough for my project?
Off-the-shelf (OTS) speech datasets are attractive for obvious reasons:
- Fast access
- Lower upfront cost
- Pre-existing transcripts and labels
- Benchmark-ready formats
They are excellent for:
- Proof-of-concept models
- Academic benchmarking
- Early experimentation
- Baseline ASR bootstrapping
We use them ourselves when they fit.
The catch is simple: generic corpora are, by definition, generic.
They rarely match your:
- Exact domain vocabulary
- Accent distribution
- Target languages
- Real-world acoustic conditions
- Legal or regulatory requirements
And this misalignment is not theoretical.
Research and industry commentary consistently show that models trained on benchmark datasets often underperform when deployed into real-world production environments with different speaker demographics and noise conditions.
Koenecke et al., Racial disparities in automated speech recognition, PNAS (2020).
The study found that commercial ASR systems had error rates nearly 2× higher for Black speakers compared to white speakers in the evaluated dataset.
The lesson is not that benchmarks are useless.
It’s that benchmark alignment is not production alignment.
Where do off‑the‑shelf datasets usually fall short?
Based on both our experience and public commentary on open and commercial speech corpora, gaps typically cluster in four areas:
1. Domain vocabulary
Generic datasets often lack:
- Financial compliance terminology
- Medical jargon
- Industry-specific acronyms
- Internal product names
Even small vocabulary gaps can significantly increase word error rates in production.
2. Accents and demographics
Many widely used corpora skew toward:
- Standardized broadcast accents
- Younger speakers
- High-resource languages
Under-representation of regional accents or older speakers leads to predictable performance gaps.
Research into speech bias repeatedly confirms this pattern.
Tatman (2017), “Gender and Dialect Bias in YouTube’s Automatic Captions.”
Demonstrated measurable performance differences across dialect groups.
Again, this doesn’t make OTS datasets “bad.”
It means they were built with different objectives.
3. Environmental mismatch
Many public corpora consist of:
- Clean, read speech
- Studio-quality audio
- Minimal background noise
Production environments often involve:
- Call-center compression artifacts
- In-car noise
- Overlapping speakers
- On-device microphones
- Code-switching in casual speech
Even small acoustic mismatches can degrade ASR accuracy significantly.
Mozilla’s Common Voice project, for example, was created specifically to increase diversity in accents and recording conditions because existing corpora lacked that coverage.
Its very existence underscores the gap that previously existed in open speech datasets.
4. Provenance and licensing risk
As AI regulation increases, another issue becomes more visible:
- Was consent properly obtained?
- Is commercial usage clearly allowed?
- Can you trace where the data originated?
Many older or scraped corpora lack:
- Clear demographic documentation
- Explicit consent flows
- Defined licensing boundaries
This may not matter for research.
It can matter significantly in regulated commercial deployments.
How does custom speech data complement off‑the‑shelf corpora?
Our philosophy at Andovar is pragmatic:
Custom data is always better where it matters most —but building everything from scratch is rarely efficient.
The strongest strategy is usually hybrid.
In practice, that looks like:
- Use OTS corpora to train a general ASR foundation.
- Evaluate against real-world traffic.
- Identify demographic, acoustic, or domain gaps.
- Run focused custom speech data collection to close those gaps.
- Attach robust metadata and consent documentation to the custom portion.
This approach:
- Controls cost
- Improves performance
- Strengthens regulatory defensibility
- Reduces bias risk
- Preserves speed-to-market

What does a realistic hybrid data strategy look like?
A practical hybrid strategy often follows this pattern:
1. Start with OTS
Bootstrap a model using well-documented, appropriately licensed datasets.
2. Measure real-world gaps
Evaluate performance across:
- Accent groups
- Age bands
- Noise environments
- Domain terminology
Avoid relying solely on benchmark scores.
3. Invest in Precision
Design targeted custom speech data collection projects for:
- Under-served accents
- High-risk regulatory domains
- Noisy real-world scenarios
- Low-resource languages
This is where multilingual voice data collection services and structured annotation workflows add the most value.
4. Standardise documentation
Maintain:
- Metadata schemas
- Consent records
- Licensing documentation
- Demographic tagging
This creates a traceable “provenance anchor” in your pipeline — something increasingly important in procurement and compliance reviews.
Why Hybrid Is Often the Most Rational Choice
From a cost perspective:
- OTS reduces initial data acquisition cost.
- Custom avoids expensive downstream performance failures.
- Hybrid minimizes over-collection.
From a performance perspective:
- OTS gives broad phonetic coverage.
- Custom optimizes for your actual users.
From a regulatory perspective:
- OTS can be efficient — if well licensed.
- Custom gives explicit consent traceability where risk is highest.
As AI regulation evolves globally, companies are increasingly asked to demonstrate where their training data came from. A fully opaque training pipeline is becoming a business liability.
Hybrid strategies reduce that exposure without over-engineering the entire dataset from day one.
Key takeaways
- Off-the-shelf speech data is an excellent starting point, but it rarely aligns perfectly with your domain, accents, environments, or regulatory constraints.
- Research consistently shows that demographic imbalance and domain mismatch can lead to significant real-world performance gaps.
- A hybrid approach—using OTS for baseline coverage and custom speech data for high-risk or high-value gaps—is typically the most cost-effective and defensible strategy.
- As provenance and ethics become procurement-level concerns, having part of your pipeline built on clearly documented, consented, traceable speech data will be a competitive advantage.
- The goal isn’t to replace off-the-shelf datasets—it’s to know where they stop being enough.
Ready to move from generic to domain‑ready ASR?
We can help you choose suitable off‑the‑shelf speech datasets, design custom speech data collections for your domains, and set up an ongoing adaptation loop that keeps your models aligned with real‑world usage.
Plan my hybrid ASR data pipeline
Chapter 10
How is voice data used across different industries?
Why does each industry need its own voice data strategy?
Voice AI is not one-size-fits-all.
A banking IVR, a hospital dictation system, an in-car assistant, and a game voice moderation tool may share similar model architectures—but they require fundamentally different speech datasets.
Industry analyses on multilingual audio datasets consistently show that use-case-specific corpora outperform generic datasets in specialized deployments. Performance depends not just on model size, but on:
- Domain vocabulary
- Accent coverage
- Environmental realism
- Regulatory constraints
- Risk tolerance
We see this directly in projects across finance, customer service, consumer electronics, and regulated sectors.
The model may be shared.
The data strategy cannot be
Finance and banking: accuracy, security, and compliance
In financial services, voice intersects with:
- Compliance monitoring
- Fraud detection
- Identity verification
- High-value customer interactions
That raises the bar significantly.
Financial institutions increasingly use voice for authentication. According to industry research:
MarketsandMarkets, Voice Biometrics Market Forecast
The global voice biometrics market is projected to grow from $1.3 billion in 2022 to over $4 billion by 2027, driven heavily by banking and financial services adoption.
That growth reflects increasing trust—but also increasing risk.
What finance datasets must handle:
- Complex domain terminology
- Names, institutions, and financial products
- High noise levels in real call-center environments
- Strong demographic coverage to reduce bias risk
- Strict consent and traceability requirements
Research on ASR domain adaptation consistently shows that models fine-tuned on in-domain call-center audio significantly outperform those trained purely on generic corpora.
The practical takeaway:
OTS datasets help you bootstrap.
Custom speech data reflecting your real customer base closes the performance gap.
Customer service and contact centers: scale and sentiment
Contact centers generate enormous volumes of voice data.
According to Gartner research, Gartner predicts that conversational AI will reduce contact center agent labor costs by $80 billion globally by 2026.
This scale makes speech data foundational to:
- Automatic transcription
- Real-time agent assistance
- QA automation
- Sentiment detection
- Intent recognition
- Compliance monitoring
Where datasets often fall short:
- Insufficient multilingual coverage
- Weak accent representation
- Poor speaker diarization (agent vs customer separation)
- Limited sentiment and outcome annotation
In this domain, custom voice data becomes especially important when:
- Expanding into new markets
- Supporting regional accents
- Moving into omnichannel environments (voice notes, WhatsApp voice, etc.)
Generic English-heavy corpora rarely match the linguistic diversity of real global support operations.
Consumer electronics and virtual assistants: global reach and inclusivity
For device manufacturers and digital assistants, the challenge is scale plus inclusivity.
Voice interfaces are now embedded in:
- Smartphones
- Smart speakers
- TVs
- Appliances
- Cars
- Wearables
Statista estimates that: The number of digital voice assistants in use worldwide is expected to exceed 8 billion devices, surpassing the global population.
That level of deployment demands:
- Broad multilingual coverage
- Accent diversity
- Robust keyword spotting
- Noise resilience
- Ethical data collection at global scale
Large open multilingual corpora (such as Mozilla Common Voice) were built specifically to address gaps in accent and language diversity.
However, even large public corpora:
- May lack certain dialects
- May not reflect device-specific acoustic conditions
- May not match proprietary wake words or command structures
That’s where full custom speech data collection projects—across dozens of languages and dialects—become critical for commercial differentiation.
Healthcare: Privacy, Precision, and Sensitivity
Healthcare voice applications include:
- Clinical dictation
- Symptom triage
- Patient engagement tools
- Remote monitoring
- Accessibility tools
Unlike consumer assistants, healthcare systems must navigate:
- Protected health information (PHI)
- Regulatory constraints (e.g., HIPAA, GDPR)
- Highly technical medical vocabulary
- Emotionally sensitive conversations
ASR systems trained on generic corpora often struggle with:
- Medical terminology
- Drug names
- Specialist jargon
Domain-adapted speech models consistently show measurable gains in word error rate when trained on medical corpora.
In healthcare especially, the value of custom, ethically collected, tightly consented speech data becomes obvious.
Education and Media: Performance and Personalization
Education and media applications are growing quickly:
Education:
- Language learning
- Pronunciation scoring
- Oral testing
- Accessibility tools
Media & Entertainment:
- Dubbing and localization
- Voice cloning
- Game moderation
- Accessibility (subtitles, narration)
In these domains, nuance matters:
- Prosody
- Emotion
- Code-switching
- Regional pronunciation
Generic speech corpora often lack the diversity and metadata richness required for fine-grained feedback systems or high-quality localization workflows.
Custom data allows:
- Age-specific modeling
- Regional pronunciation targeting
- Culturally relevant prompts
- Ethical consent for voice reuse
Why industry context changes everything
Across all sectors, the pattern is consistent:
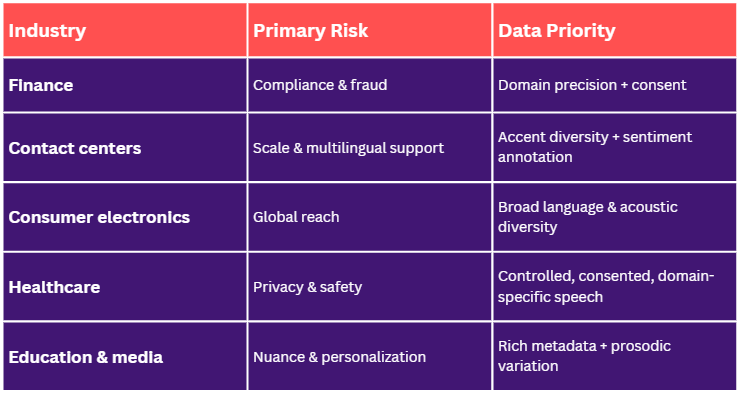
The underlying ASR technology may be similar.
But the dataset requirements are not.
The Strategic Pattern Across Industries
In almost every industry, we see the same evolution:
- Start with OTS datasets.
- Discover performance gaps in real-world traffic.
- Identify domain, accent, or environment mismatches.
- Invest in targeted custom speech data.
- Strengthen metadata, consent, and documentation for compliance.
This hybrid model balances:
- Speed
- Cost
- Performance
- Regulatory defensibility
And it allows organizations to scale voice AI responsibly.
Key takeaways
- Voice AI is highly industry-specific; domain vocabulary, regulatory context, and acoustic environments all shape what “good data” looks like.
- Finance, contact centers, consumer electronics, healthcare, education, and media each require tailored speech datasets aligned to real-world conditions.
- Research and market data consistently show that domain-adapted and demographically balanced speech corpora outperform generic datasets in production settings.
- Off-the-shelf datasets are valuable foundations—but industry-grade performance typically requires targeted custom voice data layered on top.
- A structured approach combining multilingual voice data collection, domain-specific custom speech data, and high-quality annotation is what bridges the gap between benchmarks and real products.

Final Chapter
Executive conclusion:
Building a voice data strategy that actually works
Voice AI is not a model problem. It’s a data problem.
Across this guide, we’ve covered types of speech data, industry use cases, bias, metadata, ethics, annotation, hybrid strategies, and the future of regulation. If there’s one consistent theme running through all of it, it’s this:
The biggest gains in speech AI don’t usually come from changing the model. They come from improving the data.
Teams often start with architecture decisions—transformers, self-supervised learning, multilingual encoders. But in real-world deployments, performance gaps almost always trace back to:
- Accent imbalance
- Missing domain vocabulary
- Noisy real-world conditions
- Weak metadata
- Poor annotation consistency
- Unclear provenance or consent
In other words: dataset design.
What we’ve learned about voice data in production
Across finance, healthcare, customer service, automotive, consumer electronics, and emerging markets, the same patterns repeat.
1. Bigger is not automatically better
Massive datasets help, but aligned datasets win.
A smaller corpus that reflects your users’ accents, environments, and vocabulary will often outperform a much larger generic one. Benchmark success does not guarantee production success.
2. Diversity is a performance feature
Accent coverage, language breadth, environmental variation, and demographic balance are not “fairness add-ons.” They directly impact word error rates and user trust.
When datasets are unbalanced, performance disparities are predictable. When they are deliberately designed for coverage, gaps shrink.
Diversity is not just ethical. It is technical.
3. Metadata turns audio into infrastructure
Raw audio is expensive to collect. Metadata makes it reusable.
Descriptive, technical, administrative, and structural metadata allow you to:
- Audit consent
- Filter by demographic group
- Build fair evaluation splits
- Retrain by environment
- Prove provenance
Without metadata, you have files.
With metadata, you have a strategic asset.
4. Annotation is where signal is created
Speech annotation is not just transcription. It includes:
- Speaker turns
- Timestamps
- Intent
- Entities
- Sentiment
- Acoustic events
Inconsistent annotation quietly degrades models. Clear guidelines, human-in-the-loop workflows, and quality controls protect model integrity at scale.
5. Ethics and provenance are no longer optional
Voice is inherently personal. It can reveal identity, health, emotional state, and behavioral traits.
As regulation tightens and customers ask harder questions, companies will increasingly need to answer:
- Where did this data come from?
- Do you have consent?
- Can you prove usage rights?
- Is it demographically balanced?
Organizations that treat consent, documentation, and licensing as first-class metadata will be far better positioned than those relying on opaque legacy corpora.
6. Off-the-shelf alone is rarely enough
Off-the-shelf speech datasets are valuable. They:
- Accelerate prototyping
- Lower early costs
- Provide baseline coverage
But they are generic by design.
In practice, high-performing systems almost always evolve into hybrid strategies:
- OTS for foundation
- Custom speech data for domain precision
- Targeted collection to close accent or environment gaps
- Strong annotation and metadata to maintain control
Hybrid is not compromise.
It’s optimization.
The blueprint for a strong voice data strategy
When you step back, a mature speech data strategy looks like this:
- Define real users and risk profile.
- Audit existing data (coverage, bias, licensing, metadata).
- Identify performance gaps using representative test sets.
- Use OTS corpora where appropriate.
- Design targeted custom speech data collection for critical gaps.
- Apply structured annotation and metadata schemas.
- Embed consent, licensing, and documentation into the pipeline.
- Continuously evaluate performance across demographic and environmental slices.
This is the difference between a demo and a durable product.
The future is data-centric
Speech AI is entering a data-centric era.
Model innovation will continue.
Synthetic and self-supervised approaches will expand.
Multilingual corpora will grow.
But the organizations that win will be those that:
- Treat training data as infrastructure
- Design for diversity from day one
- Invest in traceability and documentation
- Combine scale with precision
- View ethics as risk management, not marketing
Voice AI systems will increasingly be judged not only by accuracy—but by fairness, explainability, and provenance.
And those attributes are determined long before deployment.
They are determined in the dataset.
Final Thought
If you are building anything with a microphone and a model behind it, your speech data strategy is not a side decision.
It is the foundation.
High-quality, diverse, well-documented, ethically sourced voice data is what turns promising models into production-ready systems that work across languages, accents, environments, and industries.
The model may be intelligent.
But the data makes it reliable.
FAQ:
Common questions about speech and voice data for AI
What’s the difference between speech data and voice data?
We often use the terms loosely, but there’s a useful distinction: speech data focuses on the linguistic content—what was said—while voice data includes characteristics of the speaker themselves, like identity, accent, and sometimes emotion. That difference matters especially for biometrics and personalization.
When should I invest in custom speech data instead of relying on off‑the‑shelf datasets?
If you’re in a regulated industry, work in niche domains, support low‑resource languages, or have strong fairness and inclusion goals, you’ll almost certainly benefit from custom speech data. Generic corpora are great for getting started, but they rarely match your exact domain, demographics, and legal needs.
Is off‑the‑shelf speech data still worth using?
Definitely. We use off‑the‑shelf datasets to bootstrap models and reduce time‑to‑market. The key is to treat them as a baseline, then add targeted custom voice data and better annotation for the gaps that matter most to your product.
How much speech data do I need for my project?
There’s no universal number. Public and commercial corpora range from tens of hours to thousands per language, and even large datasets can perform poorly if they’re biased or misaligned with your use case. A better question is: “Do I have enough data for each key language, accent, and environment I care about?”
How does Andovar ensure speech data is ethically sourced?
We design our multilingual voice data collection services and custom speech data projects around informed consent, transparent usage terms, fair compensation, and robust privacy and security practices, aligning with widely recommended ethical guidelines for speech data. We also store licensing and consent information as metadata so you have a clear provenance trail.
Can you support low‑resource languages and less common accents?
Yes. Our global contributor network, combined with local partners, lets us recruit speakers in low‑resource languages and under‑represented accents, in line with what multilingual dataset guides highlight as critical for global speech models. We then use our studios and remote workflows to capture both clean and in‑the‑wild speech data.
How long does a typical custom speech data project take?
Timelines vary with scope—number of hours, languages, and annotation depth. Smaller pilots can run in weeks; larger multinational projects take longer. What matters most is clear scoping up front, which is also what external multilingual‑dataset guides recommend to avoid scope creep and rework.
Can you work with our existing datasets, or do you only collect new data?
We do both. We can enrich your existing corpora with better metadata and labels through our multilingual data annotation services, and we can design new custom speech data collections to complement what you already have. This aligns with the broader move towards data‑centric AI, where improving existing datasets is often as valuable as collecting new ones.
Global key takeaways
- High‑quality, diverse, and well‑documented speech data is now one of the main levers for improving speech and voice AI; the field is moving towards a data‑centric mindset where dataset design, annotation, and metadata matter as much as models.
- Custom speech data offers the best fit, performance, and provenance, but we recognise it isn’t always practical at 100% scale—so we advocate a hybrid strategy that uses off‑the‑shelf datasets for baseline coverage and custom projects for the gaps that really move the needle.
- As ethical, legal, and regulatory expectations rise, companies that invest in ethical speech data—consent‑based, licensed, traceable, and diverse—will be better positioned to ship voice products that work for everyone, not just for the easiest‑to‑serve users.

About the Author: Steven Bussey
A Fusion of Expertise and Passion: Born and raised in the UK, Steven has spent the past 24 years immersing himself in the vibrant culture of Bangkok. As a marketing specialist with a focus on language services, translation, localization, and multilingual AI data training, Steven brings a unique blend of skills and insights to the table. His expertise extends to marketing tech stacks, digital marketing strategy, and email marketing, positioning him as a versatile and forward-thinking professional in his field....More




