





A few months ago, a product team rolled out an AI feature they were genuinely excited about. The model had been trained on thousands of samples, validated through internal benchmarks and supported by what seemed like reliable AI data labeling and data annotation workflows.
But things didn’t go as planned. Within days, users began reporting inconsistent results. Voice inputs failed in certain accents. Image recognition struggled in low-light conditions. And outputs varied in ways no one had anticipated.
Initially, the ML team investigated model performance. Then, Data Operations reviewed the pipeline. Product teams escalated the issue based on user impact.
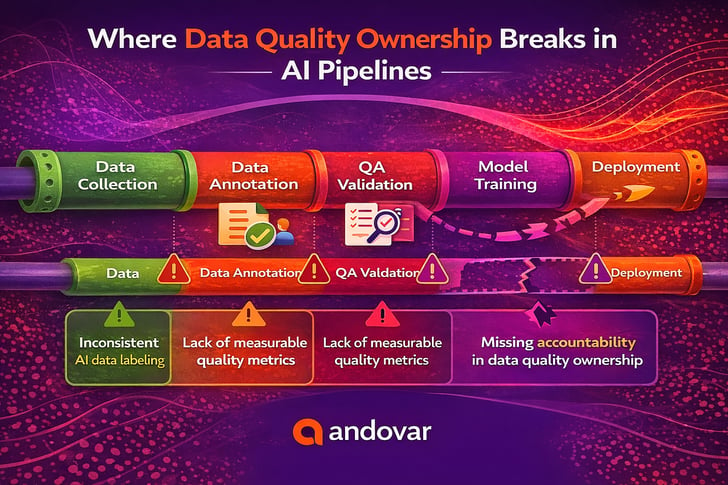
Eventually, the root cause surfaced: inconsistent data labeling, gaps in data annotation services and a lack of structured data quality management in AI. But the bigger issue? No one could clearly answer who owns data quality. This is exactly where many organizations find themselves today.
In 2026, data quality ownership is no longer just a technical responsibility. It’s a shared business challenge. As AI systems rely heavily on AI annotation tools, data annotation company workflows and large-scale data labeling service pipelines, defining accountability has become critical.
Poor data quality costs organizations an average of $12.9 million per year, reinforcing why data quality management in AI must be clearly owned and structured.
So before we break down roles like Data Ops, ML Ops and Product, let’s first understand why data quality ownership has become so complicated.
Why Is data quality ownership So Confusing in 2026?
The confusion around data quality ownership didn’t happen overnight; it’s the result of how modern AI systems, data annotation services and AI data labeling pipelines have evolved.
Today, data quality management in AI spans multiple layers:
- Data collection and preparation
- Large-scale data annotation across formats
- Automated and human-driven data labeling
- Continuous validation using AI annotation tools
As organizations adopt more advanced AI systems, they often rely on external data annotation company partners, internal ML teams and Data Ops pipelines, all working independently. The result? Ownership becomes distributed, but not clearly defined. To understand where things break down, let’s look deeper.
Has the rise of AI made data quality management in AI more complex across data annotation services?
Without a doubt.
Modern AI systems depend on multiple types of data annotation, including:
- Image annotation for computer vision systems
- Speech annotation for voice assistants and conversational AI
- Video annotation for autonomous driving and surveillance
- Text annotation for NLP and LLM training
Each of these requires specialized data labeling service workflows and introduces unique quality challenges.
For example:
- Poor image annotation can result from blur, lighting, or duplication
- Inconsistent speech annotation may include background noise or uneven decibel levels
- Weak text annotation can introduce ambiguity or bias
- Complex video annotation often suffers from temporal inconsistencies
Managing quality across all these formats makes data quality management in AI significantly more difficult and harder to assign to a single data annotation company or internal team.
Why do organizations struggle with who owns data quality in AI data labeling workflows?
From what we’ve seen across real-world deployments, the issue typically comes down to three structural challenges:
1. Fragmented data annotation services and workflows
Modern pipelines are rarely centralized.
- Data Ops manages ingestion and infrastructure
- ML teams focus on model training and evaluation
- External data labeling company partners handle AI data labeling
- Tools automate parts of the data annotation process
But no one owns the full lifecycle of data quality ownership.
2. Misaligned incentives across teams
Each function optimizes for different outcomes:
- Data teams → scalability and throughput
- ML teams → accuracy and performance
- Product teams → user experience
This creates gaps where data annotation services may prioritize speed over precision, affecting overall AI data labeling quality.
3. Over-reliance on AI annotation tools
There’s a growing assumption that AI annotation tools can solve quality issues end-to-end.
In practice:
- Automation helps scale data labeling service workflows
- But it struggles with edge cases and contextual understanding
That’s why leading organizations are combining automation with human validation—especially when working with a data annotation company.
Key Takeaways
- Data quality ownership becomes unclear when data annotation services are fragmented across teams and vendors
- The rise of multimodal data annotation (image, speech, video, text) has made data quality management in AI significantly more complex
- Poor alignment between Data Ops, ML and Product directly impacts AI data labeling quality
- AI annotation tools improve efficiency but cannot replace structured ownership and validation
- Relying solely on a data labeling company without clear governance leads to inconsistent results
- Organizations must define clear accountability to answer who owns data quality effectively
Data Ops vs ML Ops vs Product: Who Really Owns data quality ownership?
If there’s one place where the confusion around data quality ownership becomes obvious, it’s here.
Ask a Data Ops lead and they’ll say quality starts with pipelines.
Ask an ML engineer and they’ll point to training data and model performance.
Ask Product and they’ll argue that quality is defined by user outcomes.
And honestly, they’re all right. Just not completely.
The reality is that data quality management in AI doesn’t sit neatly within a single team. It’s distributed across functions, but without clear alignment, gaps start to appear especially in AI data labeling and data annotation services workflows.
Let’s break it down.
What does Data Ops own in data quality management in AI pipelines?
Data Ops plays a foundational role in data quality management in AI, even if it’s not always visible.
Their responsibilities typically include:
- Data ingestion and transformation
- Pipeline reliability and scalability
- Integration with data annotation services and storage systems
- Monitoring data flow across systems
In simple terms, Data Ops ensures that data moves efficiently from one stage to another.
But here’s the catch.
While they manage infrastructure, they usually don’t control the quality of data annotation or data labeling itself. That means issues like inconsistent image annotation or noisy speech annotation can pass through pipelines without being flagged.
So while Data Ops supports data quality ownership, it rarely owns it end-to-end.
What is ML Ops responsible for in AI data labeling and model quality?
ML Ops sits closer to the model and that changes their perspective on data quality ownership.
Their responsibilities include:
- Dataset validation and preparation
- Monitoring model performance
- Feedback loops from models to data
- Identifying gaps in AI data labeling
ML teams often feel the impact of poor data annotation services more than anyone else. When models underperform, the root cause frequently traces back to inconsistent or low-quality data labeling service outputs.
Up to 80% of model performance improvements can be attributed to better training data quality rather than algorithm tuning.
However, ML Ops doesn’t always control how the data is labeled. They depend on upstream processes whether internal teams or external data annotation company providers.
So while ML Ops influences data quality management in AI, it doesn’t fully own data quality ownership either.
Does Product ultimately define who owns data quality?
This is where things get interesting.
Product teams don’t manage pipelines or models but they own outcomes.
They are responsible for:
- User experience
- Feature performance
- Business impact
If an AI feature fails due to poor AI data labeling or inconsistent data annotation, Product is usually the first to feel the consequences.
But here’s the limitation- Product teams often lack visibility into:
- How data annotation services are structured
- How AI annotation tools are used
- Where quality breaks in the pipeline
So while Product defines what “good” looks like, it doesn’t control the process of achieving it.
| Function | Core Responsibility | Role in Data Quality | Key Blind Spot |
| Data Ops |
Pipelines & infrastructure
|
Enables data flow for data annotation services
|
Doesn’t control data labeling quality
|
| ML Ops | Model training & validation |
Identifies issues in AI data labeling
|
Relies on upstream data quality
|
| Product | User experience & outcomes |
Defines success metrics for data quality ownership
|
Limited visibility into data annotation workflows
|
Real-World Scenario
A company working on a retail AI solution faced declining model accuracy over time.
The ML team initially assumed model drift. Data Ops confirmed pipelines were stable. Product teams reported inconsistent recommendations affecting user engagement.
When the dataset was audited, the issue became clear:
- Image annotation quality had gradually degraded
- New batches from a data labeling company didn’t follow the same guidelines
- No centralized QA existed across data annotation services
The problem wasn’t the model or the pipeline. It was a breakdown in data quality ownership.
Once structured QA checks were introduced, measuring factors like image clarity, duplication, and consistency the model performance recovered within weeks.
Insight
The biggest misconception is that one team should own data quality ownership.
In reality:
- Data Ops enables
- ML Ops evaluates
- Product defines outcomes
But none of them fully own data quality management in AI, especially when data annotation services and AI data labeling are distributed.
Key Takeaways
- Data quality ownership is shared across Data Ops, ML Ops and Product but rarely clearly defined
- Data Ops supports infrastructure but doesn’t control data annotation quality
- ML Ops identifies issues in AI data labeling but depends on upstream processes
- Product defines outcomes but lacks visibility into data annotation services
- Without alignment, gaps in data labeling service workflows directly impact model performance
- Effective data quality management in AI requires coordination not isolation
Need clarity across Data Ops, ML and Product for better data quality ownership?
A structured data annotation company with managed data annotation services can bridge the gap between teams and ensure consistent AI data labeling quality.

Should data quality ownership Be Centralized or Shared in data quality management in AI?
At this point, you might be thinking: “Why not just assign data quality ownership to one team and solve the problem?”
On paper, that sounds clean. In reality, it rarely works. Modern AI systems are too complex, too distributed and too dependent on data annotation services and AI data labeling workflows for a single team to manage everything effectively. So the real question isn’t just who owns data quality It’s whether ownership should even be centralized at all.
Let’s break it down.
Can a single team truly own data quality ownership across AI data labeling pipelines?
In theory, yes. In practice, it’s extremely difficult. To fully own data quality ownership, a single team would need to control:
- Data ingestion (Data Ops)
- Model validation (ML Ops)
- User outcomes (Product)
- Execution of data annotation services
- Quality assurance across data labeling service workflows
That’s a massive scope. And here’s what usually happens when organizations try this approach:
- Bottlenecks slow down AI data labeling pipelines
- Teams lose agility
- Accountability becomes blurred again—just in a different way
Organizations with distributed data ownership models are up to 2x more likely to scale data quality management in AI than those with centralized structures.
Centralization sounds good, but it doesn’t scale well in complex AI environments.
Why does shared data quality ownership often work better in data annotation services?
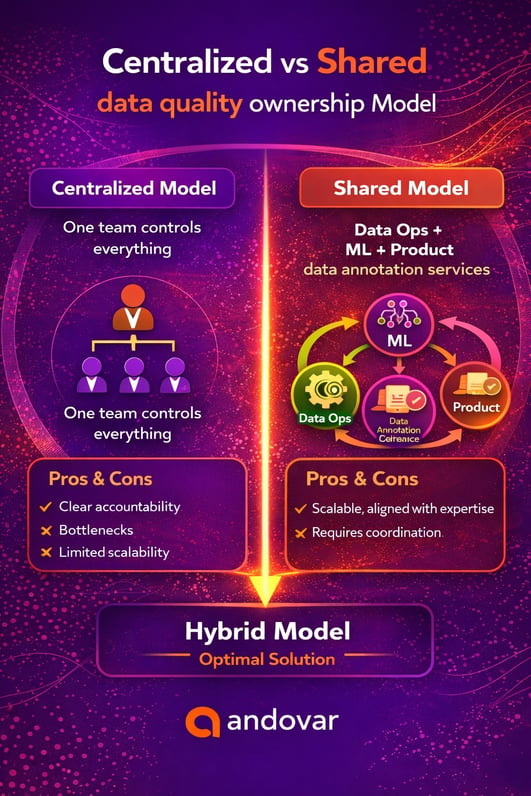
This is where most mature organizations are heading. Instead of forcing a single owner, they adopt a shared model of data quality ownership where each team is responsible for a specific layer of quality.
Here’s how it typically works:
- Data Ops → ensures pipeline reliability and data availability
- ML Ops → validates datasets and monitors performance
- Product → defines quality benchmarks and user expectations
- Data annotation company / vendors → execute data annotation services and AI data labeling
This model aligns responsibility with expertise.
And more importantly, it reflects how data quality management in AI actually works in real-world systems.
What are the risks of unclear shared ownership in data labeling service workflows?
Of course, shared ownership isn’t perfect. If not structured properly, it can lead to:
“Everyone owns it” → which often means “no one owns it”
- Inconsistent data annotation guidelines
- Misalignment between internal teams and external data labeling company partners
- Gaps in QA across AI data labeling pipelines
This is especially common when organizations rely heavily on AI annotation tools without proper governance. So the goal isn’t just shared ownership, it’s structured shared ownership.
Real-World Scenario
A global AI team attempted to centralize data quality ownership under their ML Ops function.
Initially, it worked.
But as their datasets expanded across:
The ML team became overwhelmed. They were now responsible for:
- Reviewing AI data labeling outputs
- Managing vendors
- Defining QA standards
- Monitoring model performance
Quality didn’t improve it slowed everything down. Eventually, they shifted to a hybrid model:
- Data Ops handled ingestion and validation checks
- ML Ops focused on performance feedback
- External data annotation services handled labeling with structured QA
The result
- Faster turnaround
- More consistent data labeling service quality
- Clearer data quality ownership across teams
Insight
Trying to centralize data quality ownership in modern AI systems is like trying to run an entire supply chain from one desk; it quickly becomes unmanageable. But leaving it completely unstructured creates chaos. The sweet spot lies in a hybrid approach.
Key Takeaways
- Centralizing data quality ownership often creates bottlenecks in AI data labeling workflows
- Shared ownership better reflects how data quality management in AI actually operates
- Each team (Data Ops, ML, Product) contributes to data annotation quality at different stages
- Without structure, shared ownership can lead to gaps in data labeling service quality
- Partnering with a data annotation company helps standardize execution and reduce ambiguity
- The most effective model is a hybrid approach combining ownership clarity with distributed execution
How Does data annotation Define data quality ownership in data quality management in AI?
If there’s one place where data quality ownership becomes tangible, measurable and actionable, it’s within data annotation. You can have the best models, the most advanced pipelines, and powerful AI annotation tools, but if your AI data labeling is inconsistent, everything downstream suffers. That’s because in AI systems, data annotation services don’t just support quality they define it.
Let’s unpack why.
Why is data annotation the foundation of data quality management in AI?
At its core, every AI model learns from labeled data.
That means:
- The accuracy of predictions depends on data labeling quality
- Model behavior reflects patterns in data annotation
- Biases in AI data labeling directly influence outputs
In simple terms your model is only as good as your data annotation services.
High-quality data labeling can improve model accuracy by up to 20–30%, often delivering greater gains than changes to model architecture.
This is why data quality management in AI increasingly starts at the annotation stage not after.
Who actually owns quality inside data annotation services and data labeling service workflows?
This is where things get nuanced. Within data annotation services, quality is influenced by multiple layers:
- Annotators → execute AI data labeling tasks
- QA teams → validate outputs
- Automated systems → flag inconsistencies using AI annotation tools
- Workflow managers → define guidelines and processes
But here’s the catch. Even within a single data annotation company, ownership is distributed.
Without structured workflows:
- Guidelines may be interpreted differently
- Edge cases may be handled inconsistently
- Quality may vary across batches of data labeling service outputs
This is why data quality ownership cannot stop at assigning tasks; it requires measurable, repeatable systems.
How do AI annotation tools reshape data quality ownership?
The rise of AI annotation tools has changed how data annotation services operate, but not always in the way people expect.
Today, many workflows include:
- Automated pre-labeling
- Model-assisted tagging
- AI-based validation checks
These tools improve speed and scalability of AI data labeling, but they also introduce new challenges:
- Automation can propagate errors at scale
- Models may reinforce existing biases in data annotation
- Over-reliance reduces human oversight
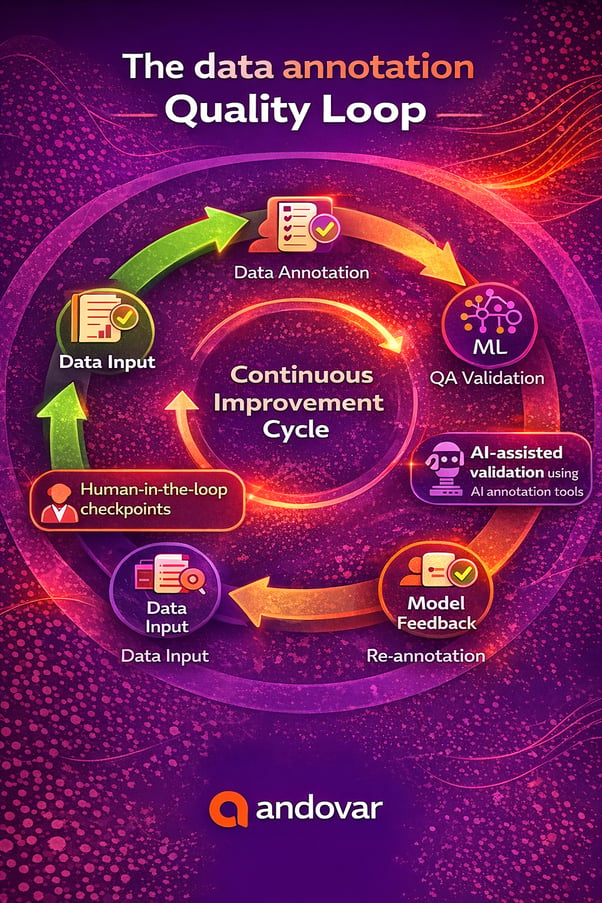
That’s why most high-performing pipelines rely on a hybrid model:
1. Automation for scale
2. Humans for validation
This combination ensures that data quality management in AI remains both efficient and accurate.
Real-World Scenario
A healthcare AI project required highly accurate speech annotation for clinical conversations. Initial results looked promising, but real-world testing revealed inconsistencies.
The issue?
- Background noise levels varied significantly
- Some recordings had low decibel clarity
- AI data labeling outputs weren’t consistently validated
Instead of relying purely on manual review, the team introduced structured QA checks:
- Audio quality scoring (DB levels, noise detection)
- Automated validation using AI annotation tools
- Human review for edge cases
The result:
- More consistent speech annotation quality
- Reduced error rates in data labeling service outputs
- Improved model performance in real-world conditions
Quality improved not by adding more people, but by structuring data annotation services properly.
Insight
You can’t fix data quality ownership at the model level if it’s broken at the data annotation level. That’s where quality is created and where it must be managed.
Key Takeaways
- Data annotation is the foundation of data quality management in AI
- Poor AI data labeling directly impacts model accuracy and performance
- Quality within data annotation services is influenced by humans, tools, and workflows
- AI annotation tools improve scalability but require human validation for accuracy
- A structured data labeling service with QA checkpoints is essential for consistent outcomes
- Effective data quality ownership must include clear accountability within data annotation company workflows
Want to improve data quality at the source?
Structured data annotation services with built-in QA, automation, and human-in-the-loop validation can ensure consistent AI data labeling across all data types.
What Role Do Low-Resource Languages Play in data quality ownership and data quality management in AI?
If data quality ownership is already complex in standard AI pipelines, it becomes even more challenging when you introduce low-resource languages into the mix. These are languages where large, structured datasets simply don’t exist at scale. And as AI adoption expands globally, more organizations are trying to build models that work beyond English and a handful of dominant languages.
That’s where things start to break.
In many cases, teams assume that scaling AI data labeling and data annotation services across languages is just a matter of translation. But that assumption often leads to poor outcomes. Because in reality, data quality management in AI is deeply tied to linguistic, cultural and contextual accuracy not just volume.
Why is data quality management in AI harder for low-resource languages in data annotation services?
The core issue is simple: lack of reliable data.
Unlike high-resource languages, low-resource environments often suffer from:
- Limited availability of training datasets
- Inconsistent linguistic standards
- Fewer skilled annotators for data annotation tasks
This directly impacts the quality of AI data labeling.
Over 90% of online content is concentrated in fewer than 10 languages, leaving thousands of languages underrepresented in AI datasets.
What does this mean in practice?
It means that when organizations attempt to scale data labeling service workflows into these languages:
- Guidelines become harder to standardize
- Annotation quality varies significantly
- Validation becomes more subjective
And ultimately, data quality ownership becomes even more blurred.
Who owns data quality ownership when working with multilingual data annotation services?
This is where traditional ownership models start to fall apart. In multilingual projects, data quality ownership is often split across:
- Internal teams defining requirements
- External data annotation company partners executing tasks
- Regional annotators interpreting language and context
The challenge is that quality isn’t just technical, it’s contextual.
For example:
A phrase in one language may carry cultural nuances that don’t directly translate. If annotators aren’t deeply familiar with the context, even well-structured data annotation services can produce inconsistent results.
This creates a situation where:
- Data Ops can’t validate linguistic accuracy
- ML teams only see the impact at the model level
- Product teams notice issues only after deployment
So the question who owns data quality becomes even harder to answer.

Real-World Scenario
A global conversational AI project aimed to expand into Southeast Asian markets. The initial rollout relied on scaled speech annotation and text annotation using existing AI annotation tools and standardized guidelines. But performance dropped significantly compared to English models.
On closer inspection:
- Local dialects weren’t properly captured
- Background noise conditions varied across regions
- Annotators interpreted intent differently
The issue wasn’t the model; it was the inconsistency in data annotation services.
Once the team introduced:
- Native-language experts
- Region-specific QA benchmarks
- Structured validation workflows
The quality of AI data labeling improved and so did model performance.
Insight
Low-resource languages expose the cracks in data quality ownership faster than anything else. They force organizations to move beyond generic pipelines and rethink how data quality management in AI is structured.
Key Takeaways
- Data quality management in AI becomes significantly more complex in low-resource language environments
- Scaling data annotation services across languages requires cultural and contextual expertise not just volume
- Poorly managed multilingual AI data labeling leads to inconsistent model performance
- Data quality ownership becomes harder to define when multiple regions, vendors, and annotators are involved
- Working with an experienced data annotation company helps standardize multilingual quality and reduce risk
What Does a Modern data quality ownership Model Look Like in data quality management in AI?
By now, one thing should be clear: There’s no single team that can fully own data quality ownership in today’s AI systems. But that doesn’t mean ownership should stay vague.
In fact, the most effective organizations are moving toward a structured, hybrid approach where data quality management in AI is clearly defined across roles, workflows and systems, especially within data annotation services and AI data labeling pipelines.
Instead of asking “who owns data quality?”, they ask a better question: “Who owns which part of data quality—and how do they work together?”
Let’s break that down.
What are the key components of a scalable data quality ownership model in AI data labeling?
A modern approach to data quality ownership typically includes three interconnected layers:
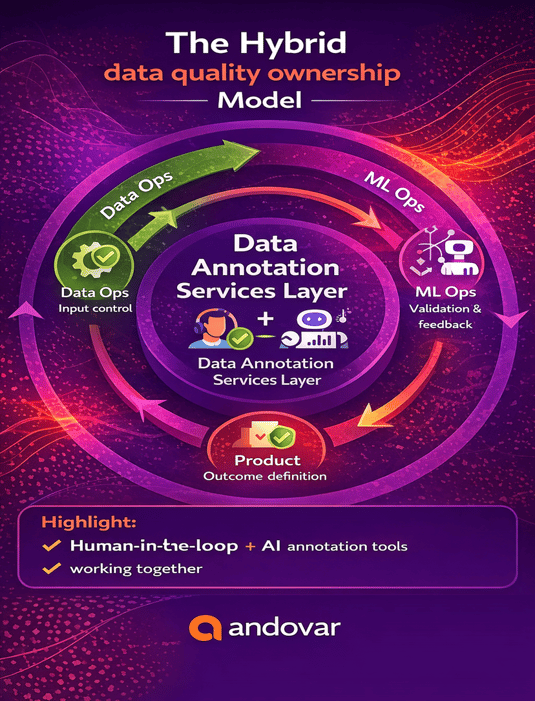
1. Upstream control (Data Ops layer)
This layer ensures that data entering the system is usable and consistent. It includes ingestion pipelines, formatting and integration with data annotation services. While Data Ops doesn’t define data labeling quality, it ensures the foundation is stable.
2. Midstream execution (Data annotation services layer)
This is where quality is actually created.
Here, data annotation, AI data labeling and data labeling service workflows determine how raw data is transformed into training-ready datasets. This layer includes:
- Annotators
- QA systems
- AI annotation tools
- Workflow orchestration
This is also where working with a structured data annotation company becomes critical, as execution consistency directly impacts downstream results.
3. Downstream validation (ML + Product layer)
This layer evaluates outcomes. ML teams assess how data annotation quality impacts model performance, while Product teams define whether outputs meet user expectations. Feedback from this stage should loop back into improving data annotation services.
Together, these layers form a continuous loop not a linear pipeline.
Why does a turnkey approach improve data quality management in AI?
One of the biggest challenges in data quality management in AI is fragmentation. When data collection, data annotation services, QA and validation are handled by different teams or vendors without coordination, quality becomes inconsistent.
A turnkey approach addresses this by connecting everything:
- Data collection and preparation
- Data annotation and AI data labeling
- QA and validation workflows
- Feedback loops from models
Integrated data pipelines and governance frameworks can improve consistency in AI outcomes by up to 50% compared to fragmented systems.
In practice, this means:
- Fewer handoff errors
- Better alignment between teams
- More consistent data labeling service quality
And most importantly, clearer data quality ownership.
How does human-in-the-loop strengthen data quality ownership in AI annotation tools?
Automation has transformed AI data labelling, but it hasn’t replaced human judgment.
In fact, the most effective systems combine:
- AI annotation tools for speed and scalability
- Human reviewers for accuracy, context, and edge cases
This approach, often called human-in-the-loop, ensures that:
- Automated errors don’t scale unchecked
- Complex scenarios are handled correctly
- Quality remains consistent across data annotation services
It also creates clearer accountability within data quality ownership, because each stage, automated or human has a defined responsibility.
Real-World Scenario
A large-scale AI project dealing with multimodal data image annotation, speech annotation and text annotation struggled with inconsistent outputs across datasets.
The issue wasn’t volume; it was fragmentation.
- Different vendors handled different data types
- QA processes varied across data annotation services
- Feedback from ML teams didn’t reach annotation workflows
To fix this, the organization shifted to a unified model:
- Centralized workflow orchestration
- Standardized QA metrics across all AI data labeling tasks
- Integrated feedback loops between ML and annotation teams
The result:
- More consistent data labeling service outputs
- Faster iteration cycles
- Stronger, more transparent data quality ownership
Insight
A modern data quality ownership model isn’t about control, it’s about coordination. The goal isn’t to assign responsibility to one team, but to create a system where every stage of data quality management in AI is clearly defined, measurable and connected.
Key Takeaways
-
Effective data quality ownership requires a structured, multi-layered approach across Data Ops, annotation and ML/Product teams
-
Data annotation services are the core execution layer where quality is created and must be tightly managed
-
Fragmented workflows lead to inconsistent AI data labeling and weak data labeling service outcomes
-
A turnkey, end-to-end approach improves consistency in data quality management in AI
-
Combining AI annotation tools with human-in-the-loop validation ensures both scalability and accuracy
- Clear feedback loops are essential to maintain strong data quality ownership
Looking for a unified approach to data quality ownership?
End-to-end data annotation services with integrated QA, automation, and human-in-the-loop workflows can help you achieve consistent AI data labeling quality at scale.

How Can Organizations Fix data quality ownership Today in data quality management in AI?
By now, it’s clear that data quality ownership isn’t broken because of a lack of tools, it’s broken because of a lack of structure. Most organizations already invest in AI annotation tools, work with a data annotation company and run large-scale data annotation services. But without clearly defined ownership, even the best systems fall short.
So how do you actually fix it?
The answer isn’t a single change, it’s a set of coordinated shifts in how data quality management in AI is approached across teams.
How do you define clear data quality ownership across AI data labeling pipelines?
The first step is clarity.
Instead of asking “who owns data quality?”, organizations need to define ownership at each stage of the pipeline:
- Data Ops → owns data readiness and pipeline integrity
- Annotation layer → owns data annotation and AI data labeling quality
- ML teams → own validation and performance feedback
- Product teams → own outcome quality and user experience
This layered ownership model ensures that data quality ownership is distributed, but not ambiguous. Without this, gaps in data labeling service workflows will continue to surface downstream.
Why should organizations standardize data annotation services and QA processes?
One of the biggest sources of inconsistency in data quality management in AI is variation in how data annotation services are executed.
Different teams or even different batches may follow slightly different guidelines. Over time, this leads to:
- Label inconsistency
- Reduced model accuracy
- Increased rework in AI data labeling pipelines
Standardization fixes this.
It creates:
- Unified annotation guidelines
- Consistent QA benchmarks
- Measurable quality across data labeling service outputs
Consistent data labeling standards can reduce model retraining cycles by up to 40% while significantly improving production performance.
In other words, consistency upstream saves time downstream.
How can AI annotation tools and human-in-the-loop improve data quality ownership?
Scaling AI data labeling without sacrificing quality is one of the biggest challenges in modern AI systems. This is where the combination of AI annotation tools and human-in-the-loop workflows becomes essential.
Automation helps:
- Speed up data annotation services
- Handle large volumes efficiently
But humans ensure:
- Contextual accuracy
- Edge-case handling
- Validation of complex scenarios
This hybrid approach strengthens data quality ownership because:
- Each stage has defined responsibility
- Errors are caught before scaling
- Quality becomes measurable, not subjective
Why is working with a data annotation company critical for scalable data quality management in AI?
As datasets grow across formats image annotation, speech annotation, video annotation and text annotation internal teams often struggle to maintain consistency. That’s where an experienced data annotation company plays a key role.
Not just in executing data annotation services, but in:
- Structuring workflows
- Defining QA benchmarks
- Ensuring consistency across AI data labeling pipelines
More importantly, they help bridge the gap between:
- Data Ops infrastructure
- ML validation
- Product expectations
Which is exactly where data quality ownership often breaks down.
What practical steps can teams take to improve who owns data quality today?
In practice, improving data quality ownership comes down to a few critical shifts:
- First, define ownership at every stage not just at the team level, but within workflows. This ensures accountability within data annotation services and data labeling service pipelines.
- Second, align KPIs across teams. Data Ops, ML, and Product should not operate in silos when it comes to data quality management in AI.
- Third, introduce measurable QA metrics. Instead of relying purely on subjective review, use structured checks across data annotation—whether it’s image clarity, audio quality, or labeling consistency.
- Fourth, build feedback loops. ML insights should directly inform improvements in AI data labeling and annotation workflows.
- And finally, invest in scalable infrastructure—combining AI annotation tools, human validation, and structured data annotation services.

Insight
Fixing data quality ownership isn’t about adding more tools or people, it’s about aligning systems, workflows and responsibilities.
Key Takeaways
- Clear ownership across pipeline stages is essential for strong data quality ownership
- Standardized data annotation services improve consistency in AI data labeling
- Combining AI annotation tools with human validation ensures scalable quality
- Working with a structured data annotation company reduces fragmentation
- Continuous feedback loops are critical for effective data quality management in AI
- Improving who owns data quality requires coordination not just delegation
Scalable, end-to-end data annotation services can help you achieve consistent AI data labeling quality across all data types.
Get started: Multilingual Data Annotation Services
Data quality ownership Is a System, Not a Role
If there’s one thing organizations are realizing in 2026, it’s this: You can’t assign data quality ownership to a single team and expect everything to fall into place. It doesn’t work that way anymore.
Modern AI systems are built on layered workflows data pipelines, data annotation services, AI data labeling, model validation and product feedback loops. Each of these plays a role in shaping outcomes, which means data quality management in AI is inherently shared. But shared doesn’t mean vague.
The organizations that get this right are the ones that treat data quality ownership as a system:
- Clearly defined responsibilities across Data Ops, ML and Product
- Structured execution through data annotation services
- Measurable QA processes within data labeling service workflows
- Continuous feedback loops powered by real-world performance
And perhaps most importantly, they understand that quality doesn’t start at the model it starts at data annotation. Because at the end of the day, every AI system is only as reliable as the data it learns from.
That’s why forward-thinking teams are moving toward hybrid approaches:
- Combining AI annotation tools with human validation
- Working with experienced data annotation company partners
- Building scalable, end-to-end workflows for AI data labeling
Not to shift responsibility but to make data quality ownership actually work.
Still unsure who owns data quality in your AI pipeline?
A structured approach to data annotation services can help you define ownership, improve consistency and scale AI data labeling with confidence.
FAQs
Q1. Who owns data quality in AI organizations?
There is no single owner of data quality ownership in modern AI systems. Responsibility is typically shared across Data Ops (data pipelines), ML teams (model validation), Product (outcomes) and data annotation services (execution of AI data labeling). The key is to clearly define ownership at each stage of data quality management in AI.
Q2. What is data quality management in AI?
Data quality management in AI refers to the processes, tools and workflows used to ensure that training data is accurate, consistent and reliable. This includes data annotation, data labeling service quality checks, validation and continuous improvement of datasets used in machine learning models.
Q3. Why is data annotation critical for data quality ownership?
Data annotation is where raw data is transformed into structured training data. Poor AI data labeling directly impacts model performance, making data annotation services a core component of data quality ownership and overall data quality management in AI.
Q4. How do data annotation services improve AI data labeling quality?
Well-structured data annotation services provide:
- Standardized guidelines
- QA validation processes
- Scalable workflows
This ensures consistent AI data labeling and reduces errors in data labeling service outputs, leading to better model performance.
5. What is the role of AI annotation tools in data quality management in AI?
AI annotation tools help automate parts of data annotation and AI data labeling, improving speed and scalability. However, they must be combined with human validation to ensure high-quality outcomes and maintain strong data quality ownership.
Q6. How do you ensure quality in image annotation and speech annotation?
Ensuring quality in image annotation and speech annotation requires:
- Clear annotation guidelines
- Automated QA checks (e.g., blur detection, noise levels)
- Human-in-the-loop validation
These practices improve consistency in data annotation services and strengthen data quality management in AI.
Q7. What are the benefits of working with a data annotation company?
A professional data annotation company provides:
- Scalable data annotation services
- Expertise across image annotation, text annotation, video annotation and speech annotation
- Structured QA processes
This helps organizations improve AI data labeling quality and establish stronger data quality ownership.
Q8. How can organizations fix who owns data quality?
To fix who owns data quality, organizations should:
- Define ownership at each stage of the pipeline
- Standardize data annotation services and QA processes
- Use AI annotation tools with human validation
- Establish feedback loops between ML and annotation workflows
This creates a clear and scalable approach to data quality management in AI.
Final Thought
At the end of the day, data quality ownership isn’t about pointing to one team, it’s about building a system where data quality management in AI is shared, structured and continuously improved. As AI becomes more dependent on data annotation services and scalable AI data labeling, the organizations that succeed will be the ones that treat data quality as a living process, not a one-time checkpoint. Get the foundation right at the data annotation stage, align teams around clear responsibilities and everything downstream from models to user experience starts to fall into place.
If you enjoyed reading this blog, head over to our full-length playbook on Data Labeling & Annotation:
2026 Data Annotation & Labeling Playbook

About the Author: Steven Bussey
A Fusion of Expertise and Passion: Born and raised in the UK, Steven has spent the past 24 years immersing himself in the vibrant culture of Bangkok. As a marketing specialist with a focus on language services, translation, localization and multilingual AI data training, Steven brings a unique blend of skills and insights to the table. His expertise extends to marketing tech stacks, digital marketing strategy, and email marketing, positioning him as a versatile and forward-thinking professional in his field....More




