





Your voice AI nails accents in 50 languages, but it chokes when a user's frustrated tone clashes with their words during a video call. That's multimodal AI in a nutshell—systems that blend voice, video, text, and more for human-like smarts. But here's the kicker: as these models explode in popularity, ethical pitfalls multiply faster than you can say "privacy breach. In short, AI is no longer just listening it’s observing, correlating and inferring.
At Andovar, we've seen it firsthand. Our clients in healthcare, finance and customer service started with solid multilingual voice data collection services, only to hit walls when scaling to full multimodal setups. Why? Voice data alone misses the full picture—facial cues, gestures, even sensor feeds from wearables. Skipping ethics here isn't just risky; it's a fast track to lawsuits, bias scandals and flops.
In this 2026 deep dive, we'll unpack why multimodal AI data demands a rethink of voice data ethics. Drawing from our work with global teams and our eight professional recording studios, we'll share real-world fixes. Expect case studies, stats and actionable steps to build ethical AI datasets that actually perform.
The Rise of Multimodal AI Systems: From Chatbots to Super Perceivers
Multimodal AI isn't some sci-fi dream anymore; it's reshaping industries from healthcare to customer service. These systems process multiple data types simultaneously voice, images and text to mimic human-like understanding. Take self-driving cars: they don't just listen to horns; they scan roads via cameras and sensors.
Multimodal models could unlock $2.6 trillion to $4.4 trillion in value annually across sectors. We've seen this firsthand at Andovar, helping clients build AI that handles real-world chaos, like emotion detection in call centers using voice tones plus facial cues.
But as these systems explode projected to grow at 30% CAGR so do ethical pitfalls. Voice data was our starting point but layering on visuals and biometrics amps up the stakes.
Why Is Multimodal AI Taking Over?
Ever wonder what makes it tick? It's the fusion: a single model like Google's Gemini or OpenAI's GPT-4o crunches text, audio and video for richer insights. In our work, we've collected off-the-shelf datasets that evolve into multimodal powerhouses.
How Does It Transform Industries?
Healthcare: Voice + scans spot issues 22% faster.
Retail: Gestures + queries personalize shops.
Auto: Sensors + voice prevent accidents.
5 Industry Shifts
- Healthcare diagnostics up 22%.
- Customer service satisfaction +35.
- EdTech engagement +28%.
- Finance fraud cuts 40%.
- Robots sync 25% better.
| Industry | Key Shift | Improvement Stat | Andovar Example |
| Healthcare | Diagnostics speed | 22% | Voice + scans |
| Customer Service | Satisfaction | 35% | Tone + facial cues |
| EdTech | Engagement | 28% | Gestures + text |
| Finance | Fraud reduction | -40% (or 42% per client) | Voice + text |
| Robotics/Auto | Sync/accident prevention | 25% | Sensors + voice |
One Andovar client in finance used our multilingual voice data collection services + text fraud down 42%.
What Is Multimodal Data?
Multimodal data is the combo platter of inputs: voice for tone, text for words, video for expressions, gestures for movement and sensors for biometrics. Humans naturally interpret the world through sight, sound, touch and context.
Multimodal AI attempts to replicate this by combining heterogeneous data sources so that meaning emerges not from one signal alone, but from the relationships between them. It's what makes AI "get" you. At Andovar, we blend these ethically using our annotation teams.Voice alone? It's 38% of emotion per Mehrabian. Add visuals and it's complete.
Breaking Down Types of Multimodal Data:
Modern multimodal systems typically integrate five major categories of data. Each comes with unique benefits and ethical challenges.
Voice Data
Speech captures words, tone, accent, rhythm and emotional cues. It is foundational for conversational AI but also deeply personal, making voice data ethics a critical consideration.
It captures:
- Speech content
- Accent and language
- Emotional tone
- Speaker identity markers
- Environmental context
Voice data is inherently biometric. Unlike passwords, voices cannot simply be changed if compromised. This makes voice data ethics especially critical.
Organizations often turn to specialized providers such as Andovar’s multilingual speech solutions to collect high-quality datasets across diverse languages while ensuring contributor consent and privacy safeguards.
If you need tailored datasets, our custom speech data services can support.
Text Data
Written language provides semantic clarity, historical context and structured information. Text often complements speech by capturing intent that may not be audible. Text includes:
- Transcripts
- Chat logs
- Emails
- Social media posts
- Metadata labels
Text data may appear less sensitive, but it can reveal identity through writing style, personal details or contextual clues. It also carries significant bias risks if datasets are not representative.
Multilingual annotation services play a key role in ensuring accuracy and cultural nuance across languages — an area where Andovar supports global AI deployments.
Video and Image Data
Visual inputs reveal facial expressions, Body language, surroundings and object interactions. Facial recognition and emotion detection rely heavily on these modalities. Facial data is considered highly sensitive biometric information under regulations such as GDPR. Improper use can lead to surveillance concerns and discrimination risks.

Gesture and Motion Data
Hand movements, posture, eye gaze and body dynamics convey intent and engagement — crucial for AR/VR, robotics and accessibility technologies. It captures how people move — hand tracking, posture, gait and physical interactions. These patterns can uniquely identify individuals, even without facial data.
Sensor and Environmental Data
Sensors embedded in devices generate continuous streams of contextual information, including:
- GPS location
- Accelerometer readings
- Heart rate or biometrics
- Temperature
- Device usage patterns
Wearables and IoT devices make sensor data one of the fastest-growing components of multimodal AI data.
Unlike episodic recordings, sensor data often operates continuously — raising concerns about persistent surveillance.
| Modality | Typical Data Type | Example Use Case | Primary Ethical Risks | Andovar Solution |
| Voice | Audio recordings | Virtual assistants | Biometric ID, consent scope | Multilingual speech collection |
| Text | Written language | Chatbots | Bias, personal disclosure | Cultural annotation |
| Video | Facial imagery | Security systems | Surveillance, misuse | Secure video labeling |
| Gesture | Motion tracking | AR/VR interaction | Behavioral profiling | Gesture sync services |
| Sensor | GPS, biometrics | Wearables | Continuous tracking | Ethical sensor fusion |
Combining them creates "human-like" AI. We've annotated such datasets using our multilingual data annotation services to ensure quality.
Why Multimodal Data Is More Than the Sum of Its Parts?
The true power and danger of multimodal systems lies in data fusion. Individually, each modality provides partial information. Together, they can reconstruct a highly detailed profile of a person’s identity, behavior, preferences and environment.
Consider a hypothetical smart home assistant equipped with multiple sensors:
- Voice commands reveal language and emotional state
- Camera feeds reveal physical appearance
- Motion sensors reveal daily routines
- Location data reveals movement patterns
- Device logs reveal habits
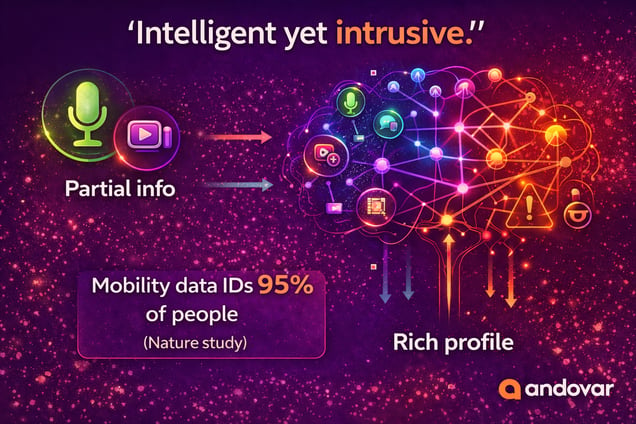
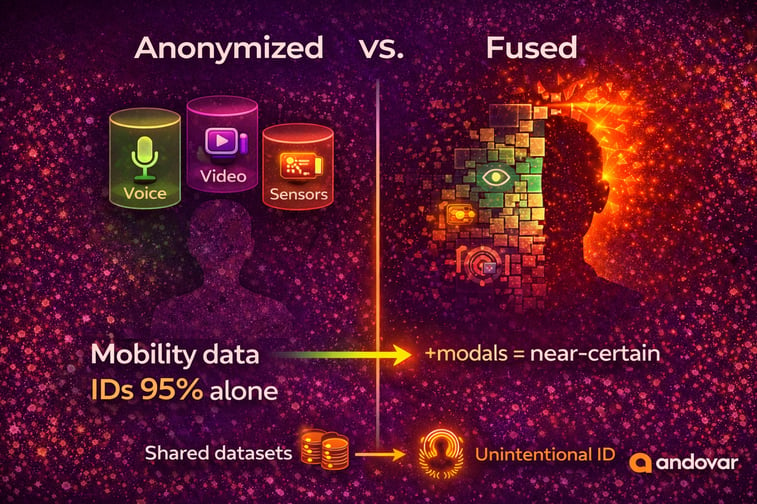
Even if each dataset is anonymized independently, combining them may allow precise re-identification.
This phenomenon has been demonstrated in multiple privacy studies. For example, research published in Nature Communications showed that mobility data alone can uniquely identify individuals with high accuracy. When combined with other modalities, identification becomes even easier.
For organizations building AI systems, this creates a paradox: The very data that makes AI intelligent is also what makes it potentially intrusive.”
How Is Multimodal Data Different from Traditional AI Data?
Traditional AI pipelines typically follow a linear pattern:
Input → Model → Output
Multimodal systems, by contrast, operate more like a network:
Multiple Inputs → Cross-Modal Fusion → Contextual Understanding → Output
For example: A customer service AI analyzing only speech may detect keywords.
A multimodal system can additionally evaluate:
- Tone and pitch variation
- Background noise (e.g., traffic, hospital sounds)
- Facial expression (if video-enabled)
- Chat history text
- Device metadata
- Emotional indicators
This richer context dramatically improves accuracy but also increases exposure to sensitive personal information.
The Role of High-Quality Annotation in Multimodal Systems
Collecting multimodal data is only the first step. Making it usable requires precise annotation across modalities.
Examples include:
- Aligning speech transcripts with video timestamps
- Labeling facial expressions frame by frame
- Tagging environmental sounds
- Identifying gestures or actions
- Synchronizing sensor events
Poor annotation leads to unreliable models but annotation itself can expose sensitive information to human reviewers if safeguards are weak.
This is why ethical AI datasets depend on controlled workflows, trained annotators and secure infrastructure. Andovar’s multilingual data annotation services are designed to support large-scale projects while maintaining confidentiality and quality standards.
How Do These Modalities Work Together?
Picture a healthcare AI diagnosing stress: voice detects tremors, video spots furrowed brows, sensors track pulse. A synergy boosts accuracy by 25-40%.

From speech alignment to video labeling across low-resource languages, Andovar delivers secure, high-quality annotation at scale.

Key Takeaways
- Multimodal data combines multiple sensory inputs to create contextual understanding.
- Voice, text, video, gesture, and sensor data are the primary modalities used in modern AI.
- Each modality carries distinct ethical risks.
- Data fusion can enable powerful insights and potential re-identification.
- Continuous sensor streams introduce new privacy challenges.
- High-quality annotation is essential for usable and responsible datasets.
Ethical Risks Multiply with Modalities
As AI systems evolve from single-input models to fully multimodal architectures, ethical risk doesn’t just increase it compounds.
Each additional data stream introduces new privacy considerations, new attack surfaces, new regulatory obligations and new opportunities for misuse. When those streams are fused, entirely new categories of risk emerge that do not exist in unimodal systems.
From Andovar’s experience supporting enterprise AI deployments, organizations often underestimate this “risk multiplier effect.” Teams may implement robust governance for voice data, only to discover that adding video, behavioural signals or sensor telemetry fundamentally changes the compliance landscape.
In short: Multimodal intelligence requires multimodal ethics.
Why More Data Types Mean More Ethical Exposure
To understand why risks multiply, consider how multimodal systems function. They don’t simply store separate datasets. They correlate them.
A typical multimodal pipeline may link:
- Audio recordings
- Video frames
- Text transcripts
- Timestamp metadata
- Device identifiers
- Location information
- Behavioral annotations
This linkage creates a rich profile of individuals and environments far more revealing than any single dataset.
Even if each component dataset is independently anonymized, combining them can restore identifying patterns. Privacy researchers often refer to this as the “mosaic effect,” where small pieces of harmless data assemble into a complete picture.
Additionally, multimodal systems increase the number of stakeholders with access to sensitive information:
- Data collectors
- Annotators
- Engineers
- Model trainers
- Third-party vendors
- Cloud providers
Each handoff introduces potential vulnerabilities.

Identity Exposure Across Modalities
Identity exposure is one of the most immediate risks in multimodal AI.
Certain modalities contain inherently biometric signals — characteristics that uniquely identify individuals.
Examples include:
- Voiceprints
- Facial features
- Gait patterns
- Behavioral signatures
- Physiological signals
Unlike passwords, biometric data cannot be changed once compromised.
When modalities are combined, identity confidence increases dramatically. A voice sample alone might narrow identification. Pair it with facial imagery and behavioral data and the probability of correct identification rises sharply.
This is why regulations such as GDPR classify biometric data as “special category” information requiring heightened protection.
| Modality | Biometric Signal | ID Confidence (Solo) | With Fusion Risk | Regulation Note |
| Voice | Voiceprints | Medium | High (unchangeable) | GDPR "special category" |
| Video | Facial features | High | Near-certain | Prohibited for some categorization |
| Gesture | Gait patterns | Low-Medium | Sharp rise | Behavioral profiling |
| Sensor | Physiological (HR) | Low | Compounds mosaic | Continuous tracking |
| Combined | All signals | N/A | Dramatic increase | Heightened protection |
Real-World Risk Scenario
Imagine a smart healthcare assistant trained on multimodal data:
- Patient speech recordings
- Facial video during consultations
- Heart rate from wearables
- Medical transcripts
Even if names are removed, linking these signals could reveal the patient’s identity — especially when combined with external data sources.
Key ethical gaps identified:
- Consent forms focused on medical use but not data linkage risks
- Insufficient explanation of biometric processing
- Lack of long-term retention policies
- Weak safeguards against secondary use
After redesigning the program with stricter controls, the provider implemented segmented data storage, enhanced consent language and independent ethical review.
| Gap Identified | Example Impact | Andovar Fix | Stat/Research |
| Narrow consent | Biometric linkage overlooked | Enhanced language on fusion | OECD transparency push |
| No retention policy | Long-term re-ID | Segmented storage | Mosaic enables surveillance |
| Weak secondary use | Reuse without disclosure | Explicit clauses | Cross-border compliance |
| Poor safeguards | Partner vulnerabilities | Ethical reviews | 7+ stakeholders exposed |
Cross-Modal Re-Identification — A Growing Threat
Perhaps the most concerning risk unique to multimodal AI is cross-modal re-identification. This occurs when separate datasets each anonymized are combined to reveal identity.
Academic research has repeatedly demonstrated that anonymization is fragile in the presence of auxiliary data. Mobility patterns alone could uniquely identify most individuals in a dataset. Adding voice or visual cues makes identification dramatically easier.
Cross-modal re-identification can happen unintentionally:
- Data shared with partners
- Datasets reused for new purposes
- Public data combined with proprietary datasets
- Model outputs revealing latent information
From a governance standpoint, this means anonymization cannot be treated as a one-time safeguard. It must be evaluated continuously as new data sources are integrated.
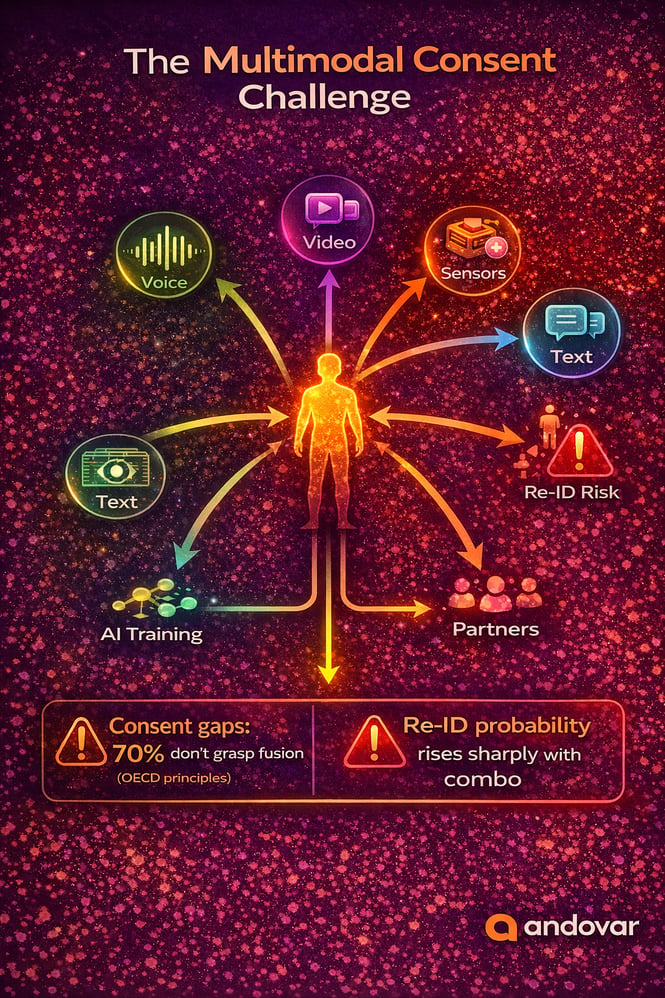
Consent Complexity in Multimodal Data Collection
Obtaining meaningful consent for multimodal data is far more difficult than for single-modality projects.
Most contributors understand what it means to record their voice. Far fewer understand what happens when that voice recording is linked to video, biometrics and behavioral data.
Key challenges include:
-
Informed Understanding- Participants may not grasp technical concepts such as data fusion or model training.
-
Secondary Use- Data collected for one purpose may later be reused for another — often legally permissible but ethically questionable without explicit disclosure.
-
Cross-Border Regulations- Consent requirements differ across jurisdictions, complicating global projects.
-
Long-Term Use- AI datasets may be retained for years or decades, far beyond contributors’ expectations.
The OECD Principles on AI emphasize transparency and accountability in data governance, highlighting the need for clear communication about how personal data will be used.
Surveillance and Behavioral Profiling Risks
Multimodal systems are uniquely capable of continuous observation.
For example, a smart workplace system might combine:
- Audio monitoring
- Video tracking
- Badge access logs
- Computer activity
- Location data
Individually, these tools may be justified for safety or productivity. Combined, they can enable pervasive surveillance.
This raises ethical concerns about autonomy, fairness and power imbalance especially in employment or public settings where participation may not be fully voluntary.
Bias Amplification Across Modalities
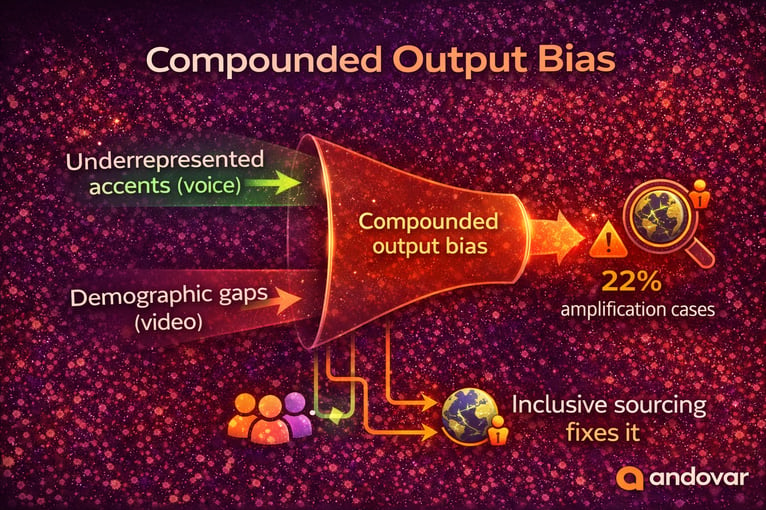
Bias in AI is not limited to datasets it can compound across modalities.
If voice data underrepresents certain accents and visual data underrepresents certain demographics, the combined system may perform disproportionately poorly for those groups.
Ensuring representative ethical AI datasets requires deliberate recruitment strategies, especially for low-resource languages and underrepresented populations.
At Andovar, our global contributor sourcing capabilities help organizations build inclusive datasets that reflect real-world diversity rather than narrow samples.
Collecting Data Across Languages and Regions?Andovar specializes in sourcing contributors worldwide including low-resource languages while maintaining ethical standards and regulatory compliance.
Key Takeaways
- Ethical risks grow exponentially as modalities are combined.
- Biometric signals make anonymization difficult.
- Cross-modal re-identification is a major emerging threat.
- Consent becomes more complex and harder to ensure meaningfully.
- Continuous monitoring systems raise surveillance concerns.
- Bias can compound across modalities without inclusive data sourcing.
- Responsible governance must address the entire data lifecycle.
Why Voice Data Cannot Stand Alone
For years, voice data has been the cornerstone of conversational AI. Speech recognition, virtual assistants, call analytics and voice biometrics have all relied heavily on audio signals to interpret human intent. And voice remains incredibly powerful.
But in the era of multimodal AI data, relying on audio alone is like trying to understand a movie by listening through a wall. You might catch the dialogue, but you miss the expressions, the setting, the action — the context that makes meaning complete.
From Andovar’s perspective, after delivering large-scale speech datasets across dozens of languages and use cases, one trend is unmistakable: organizations that once requested audio-only corpora now increasingly require synchronized visual, textual or sensor data to achieve production-grade performance.
Voice is necessary — but no longer sufficient.
The Limits of Audio-Only Understanding
Speech carries information, but it also carries ambiguity.
Consider the sentence: “That’s just great.”
Depending on tone, context, and facial expression, it could indicate:
- Genuine satisfaction
- Sarcasm
- Frustration
- Resignation
- Relief
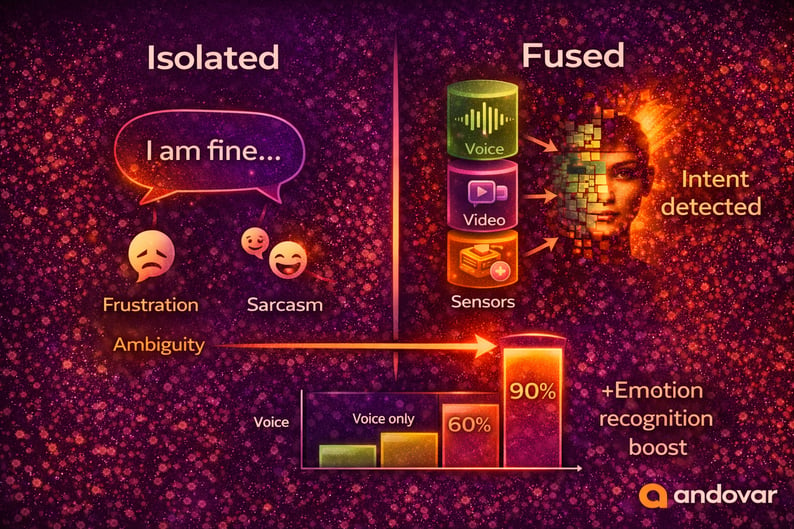
An audio-only system may struggle to differentiate between these possibilities, especially in noisy environments or cross-cultural contexts.
Audio limitations include:
- Lack of Visual Context- Speech does not reveal gestures, facial expressions, or situational cues.
- Environmental Noise- Background sounds can distort meaning or obscure critical words.
- Linguistic Ambiguity- Words alone often lack enough information to infer intent.
- Cultural Variability- Tone and phrasing differ widely across languages and regions.
Even highly advanced speech models can misinterpret intent without additional signals. This is why many modern AI deployments combine audio with contextual data streams.
| Limitation | Voice-Only Issue | Multimodal Fix |
| Visual Context | Misses gestures/expressions | Video adds facial cues |
| Environmental Noise | Distorts speech in chaos | Sensors classify backgrounds |
| Linguistic Ambiguity | Sarcasm undetected | Text history + tone fusion |
| Cultural Variability | Accent misreads | Diverse global datasets |
Contextual Understanding Requires Multiple Signals
Human communication is inherently multimodal. We rely on visual, auditory, and situational cues simultaneously often subconsciously.
AI systems aiming to interact naturally must do the same. For example:
-
Emotion Recognition- Accurate emotional inference typically requires both vocal tone and facial expression analysis.
-
Intent Detection- User intent may depend on surrounding context, not just spoken words.
-
Safety-Critical Decisions- Autonomous systems must interpret environmental signals alongside verbal inputs.
-
Accessibility Applications- Assistive technologies often combine speech with gesture or eye tracking to understand users with diverse needs.
Research in affective computing has shown that combining audio and visual features significantly improves emotion recognition accuracy compared to single-modality approaches.
Emotional and Situational Nuance
One of the biggest gaps in voice-only systems is the inability to interpret situational nuance. Imagine a customer support call where a user says, “I can’t do this anymore.”
Without context, this could indicate:
- Technical frustration
- Time pressure
- Emotional distress
- A safety concern
Multimodal inputs such as breathing patterns, background noise, facial tension (in video-enabled systems) or interaction history — can dramatically change interpretation.
This is particularly critical in sectors such as healthcare, crisis response and driver safety systems.
Case Study: Customer Support AI Misclassification (Anonymized)A large telecommunications provider deployed an AI system to triage support calls using speech analytics alone. The system flagged calls based on keywords and vocal stress indicators.
-
Distressed customers speaking calmly were not prioritized
-
Sarcastic complaints were misclassified as positive interactions
-
Background cues indicating emergencies were ignored
-
Non-native speakers were disproportionately misinterpreted
-
Chat history
-
Account activity patterns
-
Environmental noise classification
-
Behavioral indicators
Performance improved significantly, particularly for vulnerable users.”
This illustrates a key lesson:
Voice data without context can lead to ethically problematic decisions.
Safety-Critical Systems Cannot Rely on Audio Alone
In domains where human well-being is at stake, unimodal AI can introduce unacceptable risk.
-
Driver Monitoring Systems- Fatigue detection relies on eye tracking, head position, and steering behavior not just speech.
- Healthcare Diagnostics- Neurological assessments often analyze facial asymmetry, motor function and speech patterns together.
- Workplace Safety- Environmental sensors detect hazards that voice cannot convey.
- Emergency Response- Situational awareness depends on multiple data sources simultaneously.
Organizations developing these systems increasingly demand comprehensive human-centered AI data pipelines that reflect real-world complexity.
| Domain | Voice-Only Risk | Multimodal Gain |
| Driver Monitoring | Ignores drowsiness signs | Eye tracking + steering data |
| Healthcare | Misses asymmetry | Facial + speech pattern fusion |
| Emergency Response | Overlooks hazards | Sensors + situational awareness |
Language Diversity Amplifies the Need for Multimodality
Voice-only systems struggle especially in multilingual and low-resource contexts. Challenges include:
- Accents and dialect variation
- Code-switching between languages
- Limited training data for minority languages
- Cultural differences in expression
Visual and contextual signals can help compensate for linguistic uncertainty.
At Andovar, our ability to source contributors across diverse regions including low-resource languages allows organizations to build inclusive datasets that improve performance globally, not just in dominant languages.
When Voice Data Works Best — As Part of a Multimodal System
This does not diminish the importance of speech data. On the contrary, high-quality audio remains foundational for many AI applications. The key is integration.
Voice data becomes exponentially more valuable when aligned with:
- Text transcripts
- Visual context
- Environmental metadata
- Behavioral signals
- User interaction history
And this alignment must be done ethically with clear consent, secure handling and purpose limitation.
Organizations looking to build robust conversational systems often combine custom speech datasets with annotation workflows to ensure consistency across modalities.
Need High-Quality Speech Data for Multimodal AI?Andovar provides ethically sourced multilingual audio datasets designed to integrate seamlessly with visual and contextual data pipelines.
Key Takeaways
- Voice data alone cannot capture full human intent or context.
- Audio signals are inherently ambiguous without visual or situational cues.
- Multimodal inputs significantly improve emotion and intent recognition.
- Safety-critical systems require more than speech analysis.
- Multilingual environments amplify the limitations of voice-only AI.
- Speech data remains essential but most effective when integrated responsibly.
Best Practices for Ethical Multimodal Data Collection
As multimodal AI systems become more capable, the responsibility to collect data ethically becomes more complex and more critical. Organizations can no longer rely on policies designed for single-modality datasets. They must build governance frameworks that account for the interaction between voice, visual, textual, behavioral and sensor data throughout the entire lifecycle.
From our experience at Andovar supporting global enterprises, ethical success in multimodal projects rarely comes from a single safeguard. It comes from layered protections working together consent, technical controls, operational discipline, contributor respect and regulatory awareness.
Below are the core practices that distinguish responsible programs from risky ones.
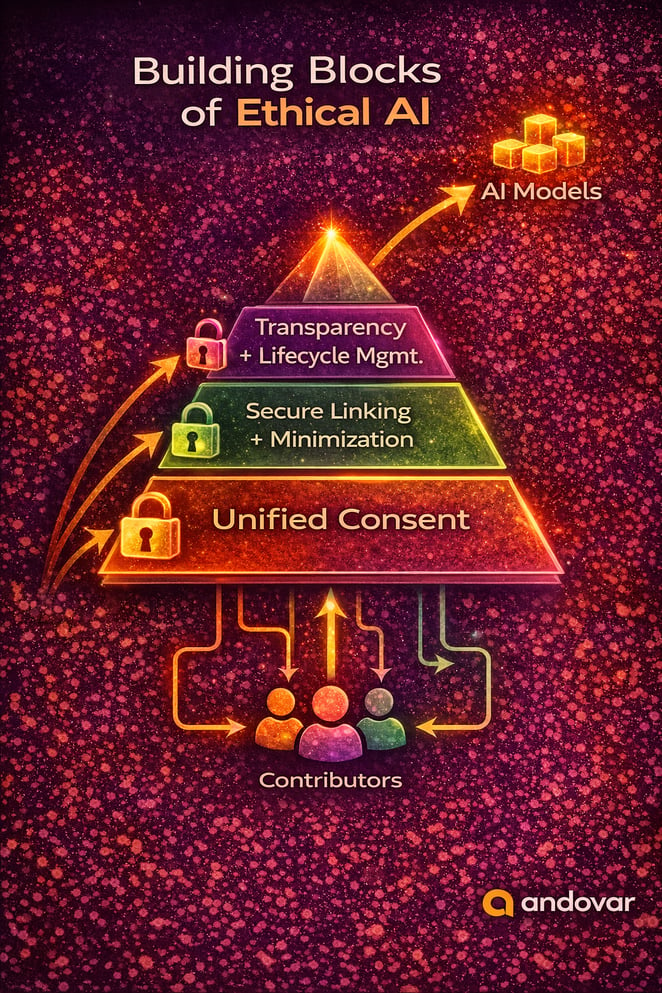
Unified Consent Frameworks
Consent is the cornerstone of ethical data collection, but traditional consent models often fall short in multimodal contexts. Many legacy forms simply state that data will be recorded for “research” or “AI training,” without clarifying how multiple data streams will be combined or reused.
In multimodal environments, contributors must understand not only that they are being recorded, but also how different modalities will interact.
A unified consent framework should clearly explain:
- What types of data will be collected (audio, video, sensors, text, etc.)
- Whether modalities will be linked together
- The intended purposes of use
- Potential future uses
- Data retention timelines
- Rights to withdraw or request deletion
Equally important is accessibility. Consent documentation must be understandable across languages and cultural contexts not buried in technical jargon.
At Andovar, we often implement layered consent models where contributors receive high-level explanations first, followed by detailed disclosures. This approach improves comprehension and aligns with global best practices for human-centered AI data governance.
Secure Modality Linking
One of the most sensitive aspects of multimodal datasets is the linkage between modalities. Connecting voice recordings to video feeds, biometric signals or behavioral metadata can create highly identifiable profiles if not handled carefully. Responsible programs avoid direct identifiers wherever possible.
Instead, they use techniques such as:
- Tokenization (replacing identifiers with random codes)
- Pseudonymization
- Segregated storage of raw and processed data
- Strict access controls
- Encryption both in transit and at rest
These measures ensure that even if one dataset is compromised, it cannot easily be combined with others to reconstruct identities.
In complex projects such as synchronized driver monitoring or healthcare analytics, we design pipelines where linkage keys are stored separately from the data itself. This reduces the risk of cross-modal re-identification while preserving usability for model training.
Purpose Limitation and Data Minimization
A common mistake in AI projects is collecting more data than necessary “just in case.” While this may seem practical from a technical standpoint, it introduces significant ethical and legal risks.
Purpose limitation a principle embedded in regulations such as GDPR requires organizations to collect data only for specific, clearly defined objectives. In multimodal settings, this principle becomes even more important because additional modalities often capture unrelated personal information.
For example:
A voice dataset collected for speech recognition might inadvertently reveal health conditions through breathing patterns. A video dataset intended for gesture analysis might expose background details about a contributor’s home environment.
Data minimization strategies include:
- Selecting only necessary modalities
- Limiting recording duration
- Avoiding continuous monitoring unless essential
- Filtering irrelevant background information
- Defining clear retention schedules
Responsible ethical AI datasets are not those with the most data but those with the most relevant data collected responsibly.
Human-Centered Contributor Recruitment
Ethical data is not just about technology; it is about people. Contributors are not abstract “data sources” they are individuals whose rights, dignity and well-being must be respected.
Human-centered recruitment practices include:
- Fair compensation
- Voluntary participation
- Clear communication of expectations
- Cultural sensitivity
- Inclusion of diverse populations
- Avoidance of exploitative sourcing
At Andovar, our global contributor network allows us to recruit participants ethically across regions, including low-resource language communities that are often underrepresented in AI datasets. This diversity improves model performance while promoting fairness.
Equally important is ensuring that participation does not expose contributors to undue risk. For example, video recordings should avoid capturing sensitive personal surroundings unless absolutely necessary.
Secure Storage and Lifecycle Management
Ethical responsibility does not end once data is collected or annotated. Multimodal datasets often persist for years, used across multiple model iterations and research initiatives.
Secure lifecycle management ensures that data remains protected from creation to deletion.
Key elements include:
- Encryption standards
- Controlled access logging
- Regular security audits
- Backup protection
- Defined retention limits
- Secure deletion protocols
Organizations should also monitor how datasets evolve over time. New analytical techniques may extract information that was not originally anticipated, creating emerging risks.
Proactive governance means periodically reassessing whether continued retention remains justified.
Transparency and Accountability
Trust in AI systems depends on transparency about how data is sourced and used. Stakeholders including users, regulators and business partners — increasingly expect clear documentation of data practices.
Transparency measures may include:
- Public data ethics policies
- Documentation of collection methods
- Disclosure of dataset composition
- Audit trails
- Independent oversight
For enterprises deploying AI at scale, ethical data practices are not just compliance requirements they are competitive advantages. Organizations that demonstrate responsible stewardship are more likely to gain user trust and regulatory approval.
| Practice | Key Actions | Andovar Strength |
| Unified Consent | Explain fusion + retention | Layered multilingual forms |
| Secure Linking | Tokenization + encryption | Segregated studio pipelines |
| Data Minimization | Limit modalities/duration | Purpose-specific collection |
| Contributor Focus | Fair pay + diversity | Global low-resource sourcing |
Building Multimodal AI Responsibly?
From contributor sourcing to annotation and delivery, Andovar provides end-to-end ethical data solutions across languages and modalities.
Key Takeaways
- Multimodal data collection requires layered ethical safeguards.
- Consent must address all modalities and their interactions.
- Secure linkage techniques reduce re-identification risk.
- Purpose limitation prevents unnecessary exposure.
- Contributor welfare is central to human- centered AI.
- Lifecycle management ensures long-term data security.
- Transparency builds trust and reduces regulatory risk.
How Andovar Enables Ethical Multimodal AI Data
Building ethical multimodal AI data pipelines requires far more than collecting recordings. It demands global reach, controlled environments, secure workflows and respect for contributors at every stage. At Andovar, we support organizations with end-to-end solutions designed to produce reliable, compliant, and human-centered datasets.
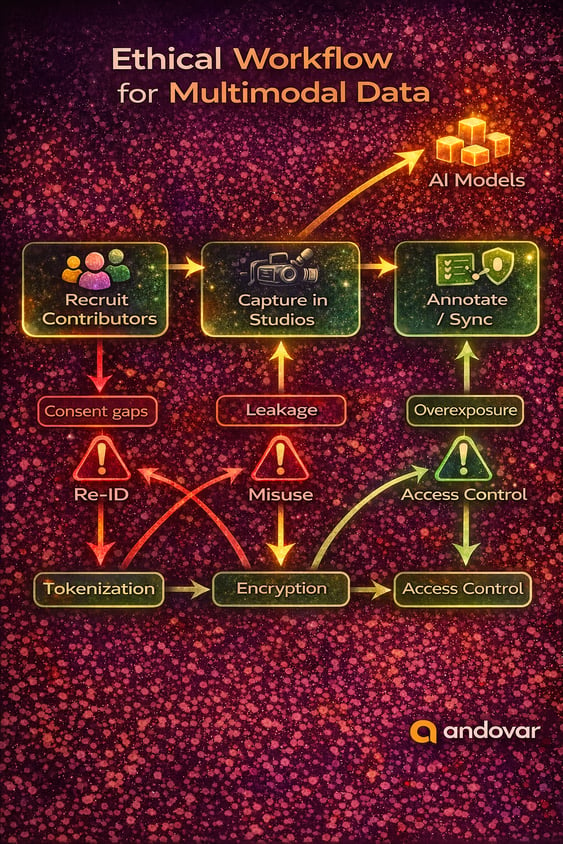
End-to-End Ethical Workflow
Fragmented data pipelines often create gaps in quality and compliance. Our integrated process covers sourcing, capture, annotation and delivery under consistent safeguards, reducing risk while maintaining scalability.
Key elements:
- Global contributor recruitment
- Regulatory-aware project management
- Quality control at each stage
- Secure data handling protocols
This approach ensures organizations receive trustworthy ethical AI datasets ready for real-world deployment.
Controlled Recording Environments
Uncontrolled recordings can expose private information or degrade quality. Andovar’s 8 professional studios enable clean, consent-verified capture for voice and video data, minimizing unintended background exposure.
This is especially important for applications in healthcare, automotive safety and biometric systems.
Global & Inclusive Data Sourcing
AI must work for everyone, not just dominant language groups. Our global network supports recruitment across regions including low-resource languages helping teams build fair and representative human-centered AI data.
Benefits include:
- Reduced bias
- Cultural authenticity
- Better global performance
- Ethical participant engagement
Multilingual Annotation & Delivery
Multimodal systems depend on accurate labeling and synchronization. Our teams provide secure annotation across languages and modalities, along with flexible delivery options custom or off-the-shelf to match project needs.
Key Takeaways
- Ethical multimodal AI requires integrated processes.
- Controlled capture improves privacy and quality.
- Diverse sourcing reduces bias.
- Accurate annotation enables reliable models.
- Flexible delivery supports rapid development.
Ethical Data Must Evolve with AI Complexity
As AI systems grow more sophisticated, ethical frameworks must advance in parallel. Models that combine speech, vision, text, biometrics and behavioral signals introduce new layers of sensitivity and risk. Traditional governance approaches designed for simple voice or text datasets are no longer sufficient for modern multimodal AI data ecosystems.
Key areas where evolution is essential include:
- Cross-modal privacy protection — safeguarding identities when multiple signals can be fused
- Bias mitigation across modalities — ensuring fairness in both visual and linguistic dimensions
- Context-aware consent — participants understanding how their data may be combined and reused
- Continuous monitoring — detecting drift, misuse or emergent harms after deployment
In addition, the shift toward real-time, adaptive AI systems means that data pipelines are no longer static. Ethical oversight must extend across the entire lifecycle from collection to training, deployment and ongoing updates. This lifecycle approach supports sustainable development of human-centered AI data strategies that remain robust as technologies evolve.
Organizations that proactively adapt will gain a competitive advantage: higher public trust, smoother regulatory navigation and more reliable system performance worldwide. Those that fail to evolve risk reputational damage, legal exposure and technical fragility.
In short, as AI becomes more complex, ethical data practices must become more comprehensive, proactive and deeply embedded into the design of intelligent systems themselves.
Conclusion
The future of artificial intelligence will be defined not only by model size or computational power but by the quality, integrity and responsibility of the data that fuels it. As systems move beyond single-modality inputs, the demand for ethical multimodal AI data, human-centered AI data and truly representative datasets becomes unavoidable. Organizations that rely solely on fragmented or convenience-based data collection risk building systems that are biased, unreliable and potentially harmful at scale.
Ethical data practices ensure that AI systems respect privacy, reflect real human diversity and perform consistently across real-world environments. From consent-driven collection to secure storage, inclusive sourcing and transparent annotation, every step in the pipeline shapes downstream outcomes. Investing in ethical AI datasets is therefore not a compliance checkbox it is a strategic requirement for trust, safety and long-term performance.
Ultimately, multimodal AI will power critical domains such as healthcare, mobility, education, finance and public services. In these contexts, errors caused by poor or unethical data can have real human consequences. Building responsible systems today ensures that tomorrow’s AI enhances society rather than undermines it.
FAQs
Q1. What is multimodal AI data?
Multimodal AI data combines information from multiple sources such as voice, text, video, gestures and sensors. So that models can interpret context more accurately than with a single data type.
Q2. Why is voice data alone not enough for modern AI?
Voice captures speech content and tone but lacks visual, environmental and situational context. Without additional signals, systems may misinterpret intent, emotion or urgency.
Q3. What are the main ethical risks of multimodal AI?
Key risks include identity exposure, biometric misuse, cross-modal re-identification, surveillance concerns, bias amplification and complex consent challenges.
Q4. How does multimodal data increase privacy concerns?
Combining datasets can reveal sensitive information that individual modalities would not expose on their own. Even anonymized data can become identifiable when fused.
Q5. What is cross-modal re-identification?
It is the process of identifying individuals by linking separate datasets for example, matching voice recordings with facial data or location patterns.
Q6. How can organizations collect multimodal data ethically?
Best practices include clear consent frameworks, data minimization, secure storage, anonymization techniques, inclusive recruitment and transparent governance policies.
Q7. Why are low-resource languages important in AI datasets?
Including underrepresented languages helps reduce bias and ensures AI systems perform effectively for global populations, not just dominant linguistic groups.
Q8. What role does annotation play in multimodal AI?
Annotation aligns and labels data across modalities, enabling models to learn relationships between signals. Poor annotation can lead to inaccurate or biased outcomes.
Global Key Takeaways
- Multimodal AI integrates multiple sensory data streams to improve understanding.
- Ethical risks grow exponentially as modalities are combined.
- Voice-only approaches are insufficient for complex real-world applications.
- Consent must address linkage and long-term use of data.
- Inclusive sourcing improves fairness and model performance.
- Annotation quality is critical for cross-modal learning.
- Secure lifecycle management protects contributors and organizations.
- Ethical governance builds trust and supports sustainable AI adoption.
Final Thoughts
Multimodal AI is not just a technological evolution it is a societal one. Systems that can see, hear, interpret and infer at scale will shape how we interact with technology, institutions and each other. The question is not whether organizations will use multimodal data, but whether they will do so responsibly. By prioritizing ethical AI datasets, respecting contributors and adopting human-centered design principles, businesses can unlock the full potential of AI while safeguarding the people behind the data.
At Andovar, we believe the future of AI depends not only on smarter models, but on better data collected with care, transparency and accountability.

About the Author: Steven Bussey
A Fusion of Expertise and Passion: Born and raised in the UK, Steven has spent the past 24 years immersing himself in the vibrant culture of Bangkok. As a marketing specialist with a focus on language services, translation, localization and multilingual AI data training, Steven brings a unique blend of skills and insights to the table. His expertise extends to marketing tech stacks, digital marketing strategy, and email marketing, positioning him as a versatile and forward-thinking professional in his field....More




